Opencv
环境配置地址:
- Anaconda : https://www.anaconda.com/download/
- Python_whl : https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
- IDE : 随便一个,可以
debug的,其余时候用jupyter
一、图像基本操作
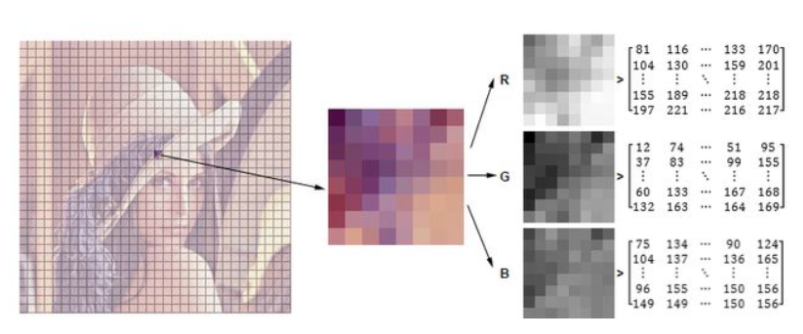
如上图 :
图片在我们肉眼五颜六色,各式各样的形状的,但是在计算机我们称为
—— 就是一堆矩阵,然后矩阵其实就是一堆数字,这些数字就是
像上面那样分成一小块,然后再细分,这样就变成一个一个像素点的形式,
一个像素点又分了三个通道 , 也就是我们熟悉的 ,分别代表红色、
绿色、蓝色 分别的像素值是多少,我们可以通过这 的不同程度的组合
可以组合出各种颜色,像素值的取值范围是 , 其中 越接近 0 是越 暗,
越 接近 255 是越 亮 ,所以如果不是三通道,如果是 的话,像素值 0
就是对应黑色 , 像素值 255 就是对应 白色 。
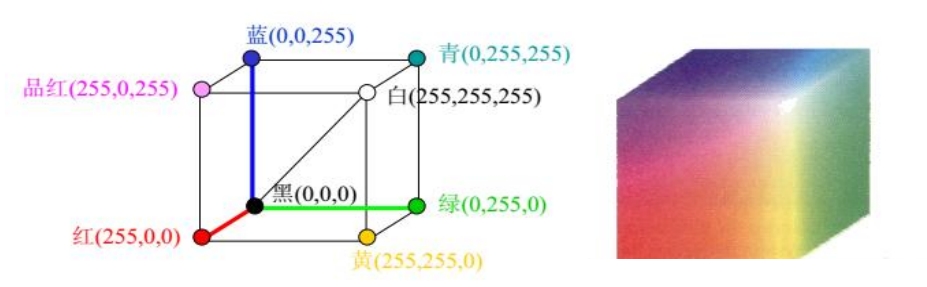
色彩三原色(CMYK):品红、黄、青
光学三原色(RGB):红、绿、蓝
数据读取-图像
使用到的
cat.jpg:

import cv2 # !!!opencv读取的格式是 BGR 不是RGB!!!
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
img=cv2.imread('cat.jpg')img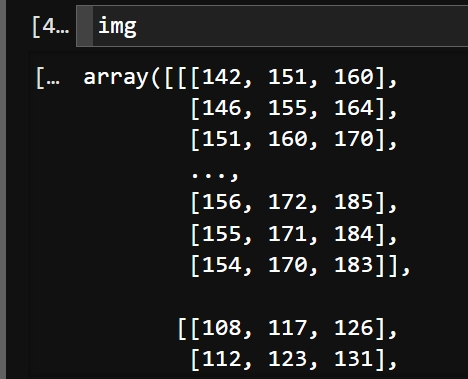
可以看出:读进去的图像就是一堆矩阵的形式
- 图像的显示
显示图像有两种方式:
- 使用
cv2会弹出一个窗口的形式来展示图像- 使用
plt可以在jupyter浏览器中渲染出来,会在单元格输出里
使用
plt展示图像之前还有一个很重要的点:

# 因为前面 img 是用cv2读进来的,所以它是BGR的形式
# 但是plt是RGB的,所以先要转换成 RGB
img2 = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.imshow(img2)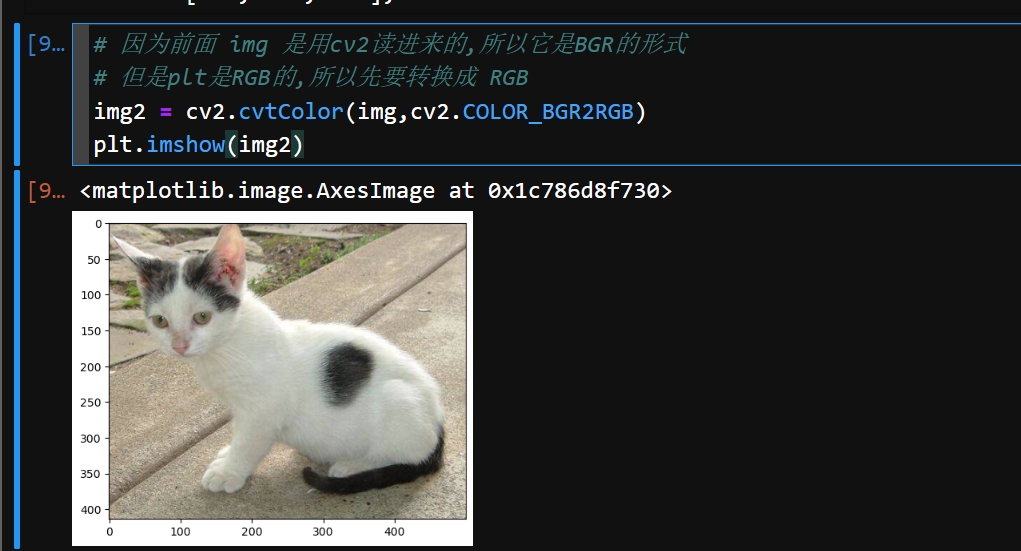
使用
cv2读的img就可以直接用cv2显示了,但是注意要有额外控制窗口的代码
# 图像的显示,也可以创建多个窗口
cv2.imshow('image',img)
# 等待时间,毫秒级,0表示任意键终止
# 其他数字 x , 代表 x 毫秒后关闭
cv2.waitKey(0)
# 一定要搭配这个使用,前一句代码本质是卡住程序而已,这个才是销毁窗口
cv2.destroyAllWindows()这一大串这么麻烦, 难道每次都要重新写这么多么,我们可以自定义一个函数
cv_show()
def cv_show(name,img):
"""
name: 窗口名字
img: 图像array
"""
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()- 图像
array的 形状
img.shape
# 输出: (414, 500, 3)
# (h 横向像素点数,w 纵向像素点数,c 通道数)- 以 灰度图 的形式读图
img=cv2.imread('cat.jpg',cv2.IMREAD_GRAYSCALE)
img# 调用前面自定义的图像显示函数
cv_show("gray_img",img)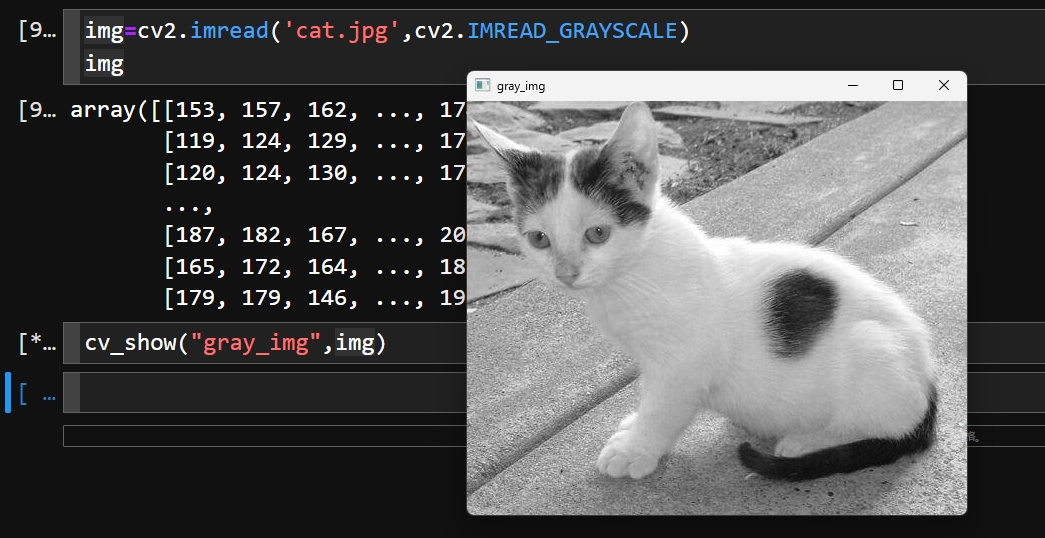
- 图像保存
#保存
cv2.imwrite('mycat.png',img)
# 输出: True- 数字图像特征
type(img)
# 输出:numpy.ndarrayimg.size
# 输出:207000
# 其实就是 414 * 500 那个矩阵的大小img.dtype
# 输出:dtype('uint8')
uint8无符号8位整数类型 , 思考一下可以发现,8位存二进制可以表示十进制0-255,也就是像素值范围
数据读取-视频
cv2.VideoCapture可以捕获摄像头,用数字来控制不同的设备,例如0,1。- 如果是视频文件,直接指定好路径即可。
# 读取视频流
vc = cv2.VideoCapture('test.mp4') # 随便找一个视频
# 如果找不到视频,并且是笔记本的话,可以读摄像头设备
#vc = cv2.VideoCapture(0)# 检查是否打开正确
if vc.isOpened():
open, frame = vc.read()
else:
open = False
open
# 输出: True# 写一个循环,一帧一帧的读视频
while open:
ret, frame = vc.read()
if frame is None:
break
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转成灰度图
cv2.imshow('result', gray) # 显示这一帧的图像
if cv2.waitKey(15) & 0xFF == 27: # Esc 键,其键码为 27, 按Esc退出
break
vc.release()
cv2.destroyAllWindows()ROI 区域
ROI (
region of interest) 即 是指在数据集中为特定目的而确定的样本。例如,在医学影像学中,可以在图像或体积上定义肿瘤的边界,以便测量其大小。
可以在图像上定义心内膜边界,例如在心脏收缩期和舒张期等不同心脏周期阶段,以评估心脏功能。
在地理信息系统(GIS)中,ROI可以被理解为从2D地图中选择的多边形区域。
在计算机视觉和光学字符识别中,ROI定义了所考虑对象的边界。
在许多应用中,ROI 上会添加符号(文本)标签,以简洁地描述其内容。
在 ROI 内可能存在个别感兴趣点(POIs)。
- 截取部分图像数据
img=cv2.imread('cat.jpg')
cat=img[0:50,0:200] # img本质是ndarray数组,那我们就可以使用切片来截取我们想要的区域
cv_show('cat',cat) # 使用前面自定义的cv_show来显示图像- 颜色通道的提取
b,g,r=cv2.split(img) # 记得cv2是BGR通道r
"""
array([[160, 164, 169, ..., 185, 184, 183],
[126, 131, 136, ..., 184, 183, 182],
[127, 131, 137, ..., 183, 182, 181],
...,
[198, 193, 178, ..., 206, 195, 174],
[176, 183, 175, ..., 188, 144, 125],
[190, 190, 157, ..., 200, 145, 144]], dtype=uint8)
"""r.shape
# (414, 500)img=cv2.merge((b,g,r)) # 再合并起来三个通道
img.shape
# (414, 500, 3)# 只保留R , 查看只有红色的图像
cur_img = img.copy()
cur_img[:,:,0] = 0 # B通道置0
cur_img[:,:,1] = 0 # G通道置0
cv_show('R',cur_img)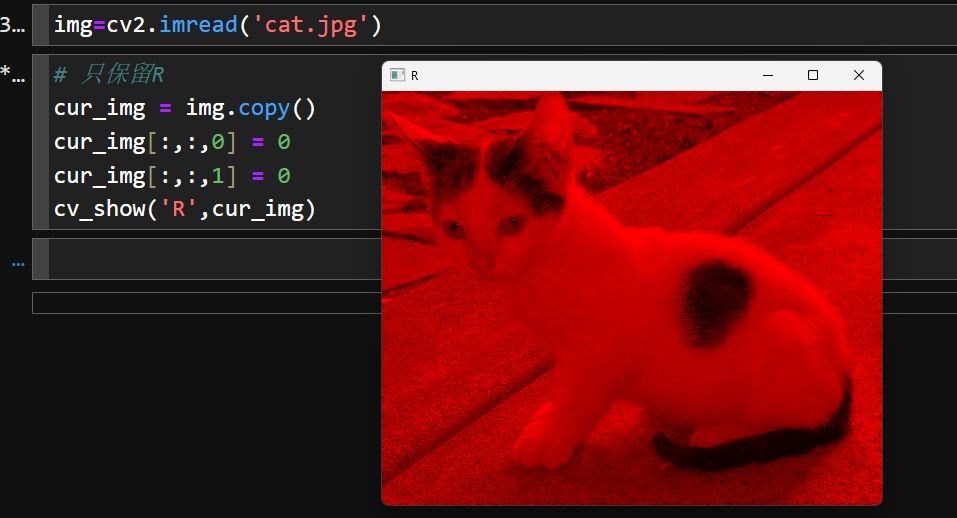
# 只保留G
cur_img = img.copy()
cur_img[:,:,0] = 0
cur_img[:,:,2] = 0
cv_show('G',cur_img)# 只保留B
cur_img = img.copy()
cur_img[:,:,1] = 0
cur_img[:,:,2] = 0
cv_show('B',cur_img)边界填充
边界填充涉及在图像边界添加额外的像素,以便在进行图像处理操作(如卷积)时,避免边界信息的丢失。
OpenCV中的
cv2.copyMakeBorder()函数可以用来实现边界填充,它允许用户指定边界的宽度和填充类型
top_size,bottom_size,left_size,right_size = (50,50,50,50) # 指定上下左右填充多大
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_CONSTANT, value=0)import matplotlib.pyplot as plt
plt.subplot(231), plt.imshow(img, 'gray'), plt.title('ORIGINAL')
plt.subplot(232), plt.imshow(replicate, 'gray'), plt.title('REPLICATE')
plt.subplot(233), plt.imshow(reflect, 'gray'), plt.title('REFLECT')
plt.subplot(234), plt.imshow(reflect101, 'gray'), plt.title('REFLECT_101')
plt.subplot(235), plt.imshow(wrap, 'gray'), plt.title('WRAP')
plt.subplot(236), plt.imshow(constant, 'gray'), plt.title('CONSTANT')
plt.show()
BORDER_REPLICATE:复制法,也就是复制最边缘像素。
BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制例如:
fedcba|abcdefgh|hgfedcb
BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,gfedcb|abcdefgh|gfedcba
BORDER_WRAP:外包装法 ,cdefgh|abcdefgh|abcdefg
BORDER_CONSTANT:常量法,常数值0 or 255( 纯黑/白 ) 填充。
数值计算
使用到的
dog.jpg

# 读图,记得cv2读图是BGR
img_cat=cv2.imread('cat.jpg')
img_dog=cv2.imread('dog.jpg')# 因为本质是 ndarray ,可以做一些数值计算
img_cat2= img_cat +10
img_cat[:5,:,0]
"""
array([[142, 146, 151, ..., 156, 155, 154],
[108, 112, 118, ..., 155, 154, 153],
[108, 110, 118, ..., 156, 155, 154],
[139, 141, 148, ..., 156, 155, 154],
[153, 156, 163, ..., 160, 159, 158]], dtype=uint8)
"""img_cat2[:5,:,0]
"""
array([[152, 156, 161, ..., 166, 165, 164],
[118, 122, 128, ..., 165, 164, 163],
[118, 120, 128, ..., 166, 165, 164],
[149, 151, 158, ..., 166, 165, 164],
[163, 166, 173, ..., 170, 169, 168]], dtype=uint8)
"""# 相当于% 256
# 因为这个数据结构本质是uint8,数据范围0-255,超出就会从0算起
(img_cat + img_cat2)[:5,:,0]
"""
array([[ 38, 46, 56, ..., 66, 64, 62],
[226, 234, 246, ..., 64, 62, 60],
[226, 230, 246, ..., 66, 64, 62],
[ 32, 36, 50, ..., 66, 64, 62],
[ 60, 66, 80, ..., 74, 72, 70]], dtype=uint8)
"""- 图像融合
# 两张图片的size不一样,如果执行这个代码就会报错:
# ValueError: operands could not be broadcast together with shapes (414,500,3) (429,499,3)
# img_cat + img_dog需要先改变成一样的尺寸,可以使用
cv2.resize()
img_cat.shape
# (414, 500, 3)img_dog = cv2.resize(img_dog, (500, 414)) # 这里传入的参数是 (w,h)别搞反了
img_dog.shape
# (414, 500, 3)变成一样的尺寸了就可以做图像融合,使用
cv2.addWeighted()其实函数名就很直观了,其实就是做了一种 的感觉
# cv2.addWeighted(src1,alpha,src2,beta,gamma)
# R = alpha * src1 + beta * src2 + gamma
res = cv2.addWeighted(img_cat, 0.4, img_dog, 0.6, 0)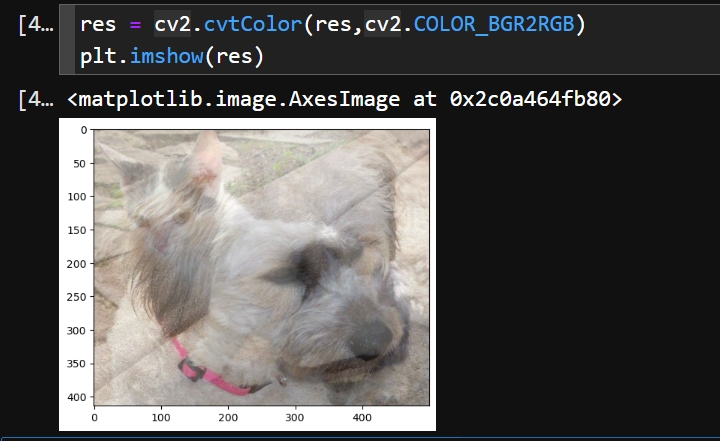
做完图像融合就像这样,又可以看到猫又可以看到狗,(怎么感觉有点像网上说的 “宿命感“~)
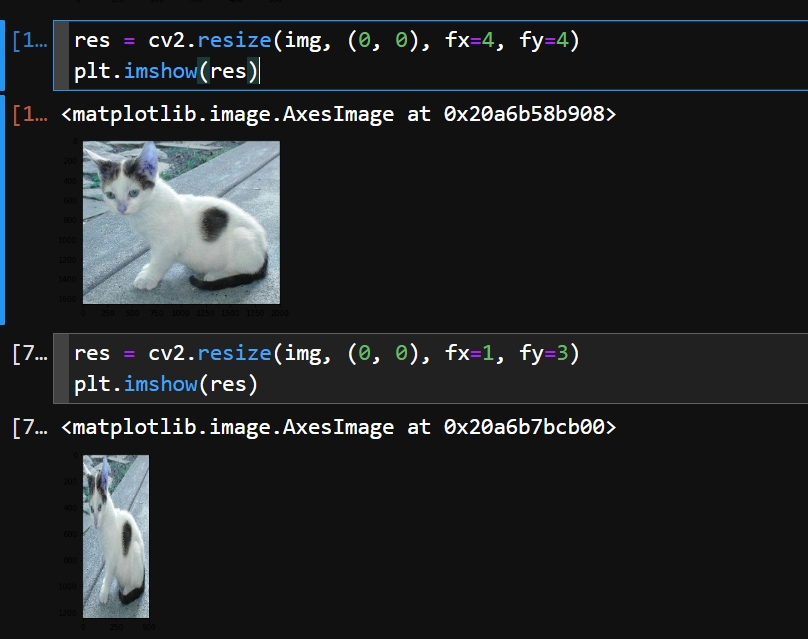
改变图像大小还可以是传入
(0,0)去尺寸部分,然后后面传入 横尺寸称几倍,纵尺寸乘几倍
res = cv2.resize(img, (0, 0), fx=4, fy=4)
plt.imshow(res)res = cv2.resize(img, (0, 0), fx=1, fy=3)
plt.imshow(res)图像色彩不对,其实本质还是那句话,
cv2是BGR,plt是RGB,这里就不换了,正好展示一下效果
二、阈值与平滑处理
图像阈值
ret, dst = cv2.threshold(src, thresh, maxval, type)
- src: 输入图,只能输入单通道图像,通常来说为灰度图
- dst: 输出图
- thresh: 阈值
- maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
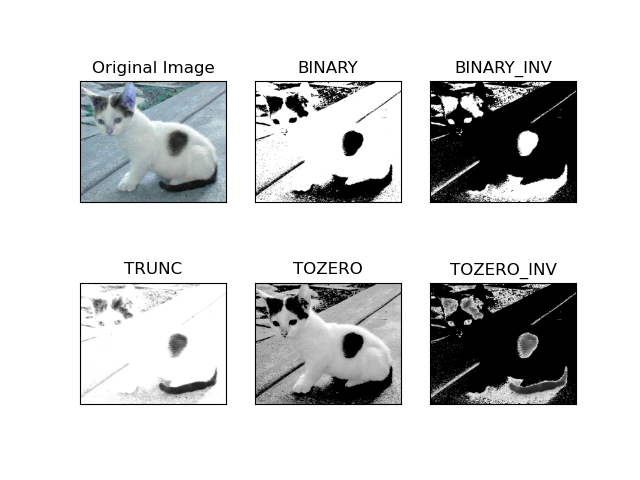
- type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV
- cv2.THRESH_BINARY 超过阈值部分取 maxval(最大值),否则取0
- cv2.THRESH_BINARY_INV THRESH_BINARY的反转
- cv2.THRESH_TRUNC 大于阈值部分设为阈值,否则不变
- cv2.THRESH_TOZERO 大于阈值部分不改变,否则设为0
- cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
img=cv2.imread('cat.jpg')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)ret, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
ret, thresh2 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY_INV)
ret, thresh3 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TRUNC)
ret, thresh4 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO)
ret, thresh5 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original Image', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()输入的
plt如下 :