Machine_Learning 🎢
一、初识Scikit-Learn
工欲善其事必先利其器,在学习算法之前,
我们首先来了解一下现阶段最完整、最流行的机器学习算法库
Scikit-Learn。
算法包、算法库、算法框架概念辨析:
:一般指单独一个或者一类算法使用的函数或者类( 比如 python 中的
Numpy / pandas):指代封装程度更高、对机器学习这一大类算法功能实现更加完整、甚至是定义了一类数据结构的代码模块(比如:
Scikit-Learn机器学习算法库):在算法库的基础上,更进一步定义基本对象类型的运行方式
(比如:
PyTorch、TensorFlow等深度学习框架)
1.1、Scikit-Learn的前世今生
- Scikit-Learn项目简介
Scikit-Learn最早是由
David Cournapeau等人在2007年谷歌编程之夏(Google Summer of Code)活动中发起的一个项目,并与2010年正式开源,目前归属 INRIA(法国国家信息与自动化研究所)。而项目取名为
Scikit-Learn,也是因为该算法库是基于SciPy来进行的构建,而Scikit则是SciPy Kit(SciPy衍生的工具套件)
的简称,而learn则不禁让人联系到机器学习Machine Learning。因此,尽管Scikit-Learn看起来不如
NumPy、Pandas 短小精悍,但其背后的实际含义也是一目了然。
经过数十年的发展,Scikit-Learn已经成为目前机器学习领域最完整、同时也是最具影响力的算法库,
更重要的是,该项目拥有较为充裕的资金支持和完整规范的运作流程,以及业内顶级的开发和维护团队,
目前以三个月一个小版本的速度在进行更新迭代。
- Scikit-Learn官网与中文社区
作为非营利性组织维护的开源项目,我们可以从 https://scikit-learn.org/stable/ 网址
登陆Scikit-Learn项目官网。
值得一提的是,对于大多数流行的开源项目,官网都是学习的绝佳资源。
而对于Scikit-Learn来说尤其是如此。要知道,哪怕是顶级开源项目盛行的当下,
Scikit-Learn官网在相关内容介绍的详细和完整程度上,都是业内首屈一指的。
无论是Scikit-Learn的安装、更新,还是具体算法的使用方法,甚至包括算法核心原理
的论文出处以及算法使用的案例,在 Scikit-Learn官网 上都有详细的介绍。
稍后将对其逐一进行详细介绍。
正是因为Scikit-Learn官网内容的完整性,国内也有许多团队试图将Scikit-Learn项目进行翻译、并建立相应的
中文社区。但遗憾的是,由于国内的大多数团队对于开源项目的维护、管理和资金运作都缺乏必要的经验,
导致诸多所谓的Scikit-Learn中文社区其实并不是真正意义上的开源社区,而是一堆过时的、不完整的、不准
确的内容翻译拼凑而成的内容网站,借着技术传播之名、行商业产品引流之实。而这也最终导致国内的
Scikit-Learn中文社区,充其量只能作为外文技术内容翻译的一个参考,而无法作为技术解释和技术学习的核
心内容。因此,围绕Scikit-Learn的内容查阅,我们更推荐直接访问外文官网 。
1.2、Scikit-Learn官网
接下来,我们围绕 Scikit-Learn 官网的基本架构与核心功能进行介绍,
并同时介绍关于 Scikit-Learn 的基本安装与使用方法。
进入Scikit-Learn官网,首先看到的是功能导航栏、
sklearn基本情况介绍以及几个核心功能跳转链接。

关于核心信息部分,我们能够看到Scikit-Learn作为开源项目的基本申明,
以及该开源项目所遵循的BSD协议。当然比较重要的一点是,
sklearn是构建在 NumPy、SciPy 和 matplotlib上的相关申明,后面我们会看到,
sklearn中核心能够处理的对象类型就是NumPy当中的数组(array),同时
sklearn中的诸多数学计算过程也都是基于SciPy中的相关功能来进行的实现。
值得注意的是,底层数据结构对算法库的影响是至关重要的,
在分布式计算框架
Spark中,算法库就有两类,其一是围绕Spark基本数据结构RDD构建的ML包,其二则是围绕Spark高级数据结构 DataSet 和 DataFrame 构建的 MLLib 包。
当然由于基于更高级的数据结构所构建的算法模型更易于使用,因此ML包已经不再更新了。
1.3、sklearn 安装与更新
接下来核心介绍功能导航栏的相关功能。
首先是关于 Scikit-Learn 的安装方法,我们可以在 Install 内进行查看:
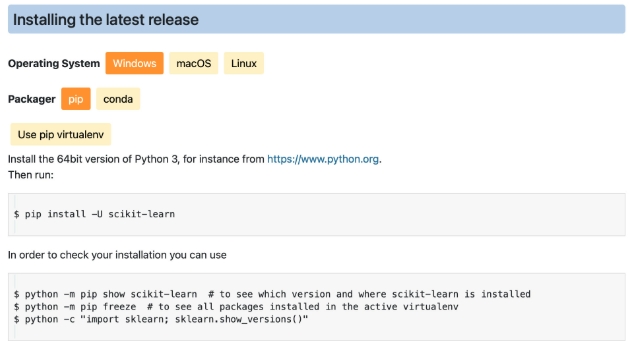
该页面主要介绍了关于 sklearn 在不同平台下、使用不同工具的安装方法。
如果是首次安装 sklearn,可参考上述代码在命令行中进行安装。
并且官网还贴心的指出,可以通过后面的代码查看sklearn的安装情况,
其中 第一行是查看目前安装的 sklearn版本以及安装位置,
第二行代码是查看安装好的第三方库(在当前虚拟环境下),
第三行代码则是查看当前已经安装好的 sklearn 版本。
当然,该页面还细心的给出了虚拟环境不同版本第三方包冲突后的解决方案,
以及sklearn的包的依赖包的安装方法,包括新版sklearn所需基础依赖包的版本号等。
另外,该页面还给出了新版sklearn的Mac M1版本的包的安装方法,由此可见sklearn官网内容的详细程度。
当然,对于 来说,
,
并且不同平台的Anaconda就已经自带了能够在对应平台运行的sklearn包,
我们可以直接通过下述语句进行sklearn版本的查看:
import sklearnsklearn.__version__ #注意:左右两个下划线
# '1.5.2'1.4、sklearn内容分布与查找
- sklearn的六大功能模块
从建模功能上进行区分,sklearn将所有的内容分为 ,
分别是 (Classification)、(Regression)、(Clustering)、
(Dimensionality reduction)、(Model selection)和 六大类。

其中 分类模型、回归模型 和 聚类模型 是机器学习内主流的三大类模型,
前两者是 有监督学习 , 聚类模型属于无监督学习范畴。
当然,sklearn中并未包含关联规则相关算法,如
Apriori或者FP-Growth,这其实一定程度上和 sklearn 只能处理
array-like类型对象有关。而后三者,降维方法、模型选择方法和数据预处理方法,主要是一些辅助建模的相关方法。
值得一提的是,上述六个功能模块的划分其实是存在很多交叉的,
对于很多模型来说,既能处理分类问题、同时也能处理回归问题,
而很多聚类算法同时也可以作为降维方法使用。
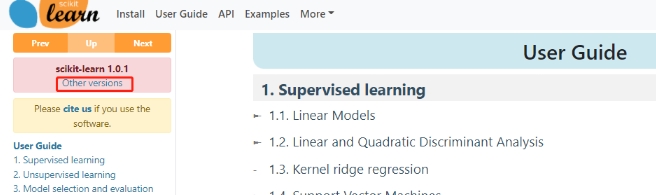
- User Guide:sklearn所有内容的合集文档
此外,我们可以在最上方的User Guide一栏进入sklearn所有内容的合集页面,
其中包含了sklearn的所有内容按照使用顺序进行的排序。
如果点击左上方的 Other versions,则可以下载sklearn所有版本的User Guide的PDF版本。
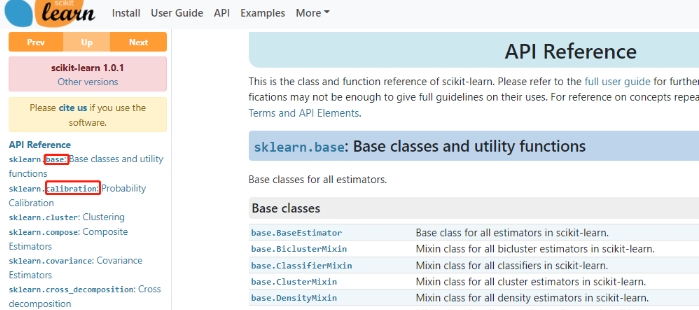
- API:按照二级模块首字母排序的接口查询文档
如果想根据所需模块的名字去查找相关API说明文档,
则可以点击最上方的 API 一栏进入到根据二极模块首字母排序的API查询文档中。
其中二级模块指的是
sklearn.后面的模块。
- Examples:sklearn中自带的一些小例子
以上就是关于sklearn官网的整体内容布局介绍,
接下来,我们将一起来看一下如何使用 sklearn 进行调库建模。
二、sklearn核心概念与快速建模流程
作为功能完整算法库,sklearn 不仅提供了完整的机器学习建模功能支持,
同时也提供了包括数据预处理、模型评估、模型选择等诸多功能,
并且支持以
Pipelines(管道)形式构建机器学习流,而基于Pipeline和模型选择功能甚至能够衍化出
AutoML(自动机器学习)的相关功能,也就是现在所谓的
Auto-sklearn。
不过在开始阶段,我们还是需要从sklearn的基础功能入手进行学习,
然后循序渐进、逐步深化对工具的理解和掌握。
- sklearn核心对象类型:评估器(estimator)
很多功能完整的第三方库其实都有各自定义的核心对象类型,
如 NumPy 中的数组(Array)、Pandas 中的 DataFrame 等,
当然这些由第三方库定义的数据结构实际上都是定义在源码中的某个类,
在调用这些对象类型时实际上都是在实例化对应的类。
对于 sklearn 来说,定义的 。
我们可以将 ,
而s klearn的建模过程 。
❓ 类:面向对象编程中的一个概念,可以简单理解为具有共同属性的一个集合。
本质上是一种引用数据类型,类似于整数int、字符串str等基本数据类型,
不同的是类是一种复杂的数据类型,并且不能被直接操作,只有被实例化为对象时,才变得可操作。
围绕评估器的使用也基本分为两步,
其一是 实例化该对象 ,
其二则是 围绕某数据进行模型训练 。
接下来,我们就尝试调用 。
首先是准备数据,此处使用的数据集(
LinearData.csv)是我们人为创造的、基本规律满足
分布的回归类数据集.

import pandas as pd
data = pd.read_csv("data/LinearData.csv")
data.head()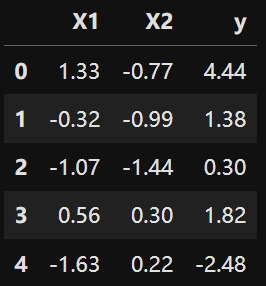
data.shape
# (1000, 3)这里需要特别强调的是,sklearn默认接收的对象类型是数组,
即无论是 特征矩阵 还是 标签数组 ,最好都先转化成 array对象类型 再进行输入。
不过,sklearn还能够处理array-like的数据,例如和数组形式相同的列表和 DataFrame,
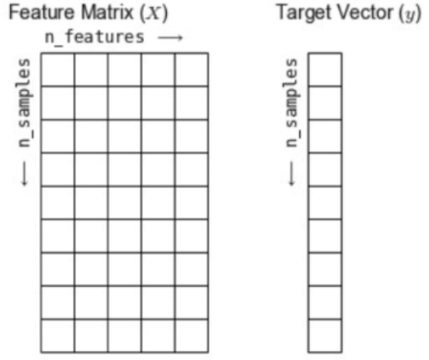
也是可以直接输入的。在sklearn中,我们往往以称特征矩阵为 Features Matrix,
称标签数组为Target Vector,并且以
n_samples表示数据行数、n_feature表示特征矩阵列数:
# 导入线性回归评估器
from sklearn.linear_model import LinearRegression# 其他导入方式
# 1. 直接导入sklearn
# import sklearn
# 然后在sklearn里面的linear_model模块内查询LinearRegression评估器
# sklearn.linear_model.LinearRegression
# 2. 直接导入sklearn内的linear_model模块
# from sklearn import linear_model
# 然后在linear_model模块内查询LinearRegression评估器
# linear_model.LinearRegression导入评估器实际上就相当于是导入了某个模块(实际上是某个类),
但要使用这个评估器类,还需要对其进行实例化操作才能进行后续的使用,
类的实例化过程会有可选参数的输入,当然也可以不输入任何参数直接实例化该类的对象:
model = LinearRegression()X = data.iloc[:,:2] #特征矩阵
X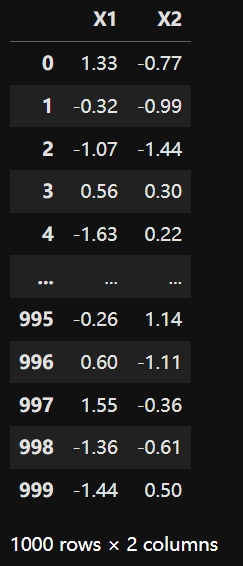
y = data.iloc[:,-1] #数组标签
y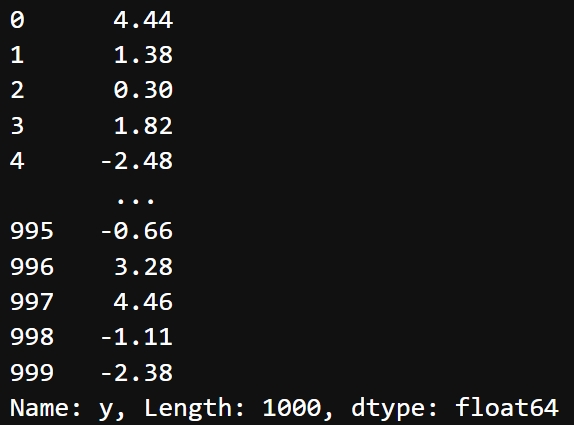
# 调用评估器中的fit方法进行模型训练
model.fit(X, y)此时
model就是一个训练好的模型 ~
fit方法是 LinearRegression 类中的一个至关重要的方法,同时也是sklearn中代表模型的评估器都具有的方法, 当 fit 方法执行完后,即完成了模型训练,
此时 。
而这些包括参数取值在内的所有模型信息,我们都可以通过调用model对象当中的一些属性来查看,
例如:
# 查看自变量参数
model.coef_
# array([ 1.99956963, -0.9996623 ])# 查看模型截距
model.intercept_
# 0.9999107670017847可见 训练好的权重和截距都很切合
至此,我们即完成了调用 sklearn 进行建模的简单流程 !
三、ML的起点:KNN
1、模型建立的基本思路
学习机器学习,永远是从 开始 —— 这是一种 的机器学习模型。
分类算法的目标是 根据样本的特征预测出样本所在的类别,
因此分类算法中的标签的类别通常使用整数来表示。
例如,如果只有 :男女,是否,正负,则我们往往使用 ,
或者使用 [1,-1] 分别表示两类。当分类的标签中含有 ,
比如说 “ 哺乳动物,软体动物,节肢动物 ”,
则我们通常将标签表示为 。
理论上来说,表示为 10,20,30 也是没什么问题的,但行业惯例是 将类别表示为从0开始的整数。
对于分类模型,我们首先需要给模型输入一组 包含特征和标签的数据 ,
计算机会依据算法的引导从这组数据中进行学习,并逐渐形成我们所需要的模型。
这个过程叫做 ,这一组被导入的数据叫做 。
学习完毕后,模型就建成了,此时我们导入 另一组数据,但这组数据中 只有特征,没有标签 。
模型会帮我们根据训练集预测出这组数据的预测标签,
我们则需要对比 和 的差异。
差异越小,证明模型的效果越好。
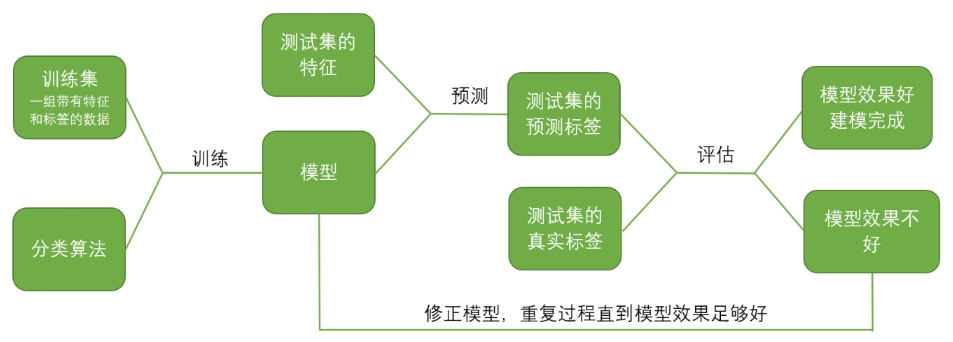
在这个流程中,要求我们将数据分解为 和 。
几乎所有的分类算法原理,都是关于模型如何在训练集上进行学习的过程。
越复杂的模型,这个学习过程越难,当学习过程变得逐渐复杂,模型也会逐渐趋向于不可解释。
因此,简单而有效的模型是机器学习界的珍宝。
KNN 就是这样的一个模型。
2、KNN 原理基础
,是机器学习算法中原理最简单的算法之一。
KNN的核心功能是解决有监督的分类问题,但也可以被用于回归之中。
作为惰性学习算法,KNN不产生模型,因此算法准确性并不具备强可推广性,
但KNN能够快速高效地解决建立在特殊数据集上的预测分类问题,因此其具备非常广泛的使用情景。
KNN的算法原理,可以简单如下描述:
一个数据集中存在多个已有标签的样本值,这些样本值共有的 。
当有一个需要
预测 / 分类的 样本 x 出现,我们把这个 x 放到多维空间 n 中,找到离其 ,并将 。
对这k个最近邻,查看他们的标签都属于何种类别,
根据 的原则进行判断, 。
其中涉及到的原理是“越相近越相似”,这也是KNN的基本假设
若数据集只有两个特征,则针对于数据集的描述可用二维平面空间图来表示。
如下图,二维平面空间的横坐标是 特征1,纵坐标是 特征2,
每个样本点的分类 。
图中给出了位于平面中心的,,并用 绿色 分别标注了 k为1,2,3时的最近邻状况。
在 中,x 的 1-最近邻 是一个负例,因此 , x 被指派到负类。
中,3-最近邻 中包括 两个正例和一个负例,根据 “ 少数服从多数原则 ” ,点x 被指派到正类。
在最近邻中正例和负例个数相同的情况下(图b),算法将 随机选择一个类标号来分类该点 。
ps: 正例和负例个数相同 也不一定完全随机的分配,可以在其他维度考虑,
比如 图b 虽然一个正例一个负例,但是负例距离是更近的,那么分类为负类则是更好的选择
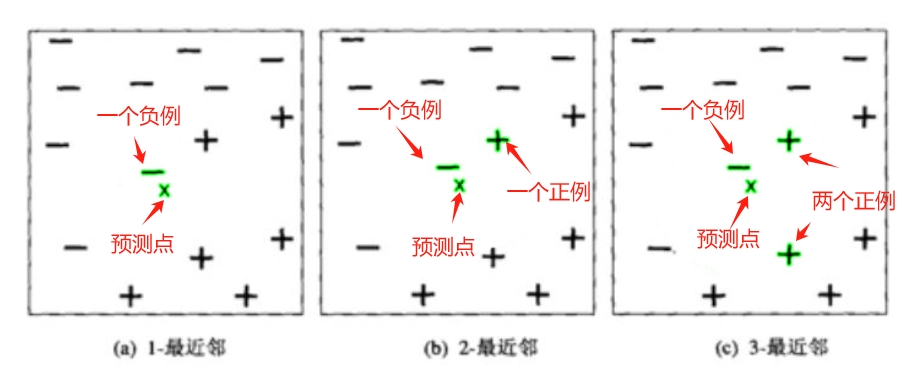
所以说 :
3、sklearn 实现 KNN
K 值的选择很关键, 它很大程度的影响我们最后的分类结果 !
sklearn的基本建模流程
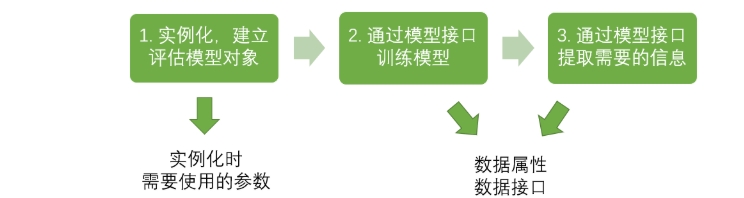
- 在这个流程下,KNN 对应的代码是:
#======注意该代码仅作展示实现框架,无法运行=======#
from sklearn.neighbors import KNeighborsClassifier #导入需要的模块
clf = KNeighborsClassifier(n_neighbors=k) #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息具体地来说,KNN 算法在 sklearn 中通过下面这个类来实现:
class :
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform',algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
其中参数 , 表示 :。
4、使用 KNN 算法完成手写数字数据集的预测
SKlearn中有很多内置的数据集:https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
这里我们选择一个手写数字的数据集,来测试KNN算法在该数据集上的预测效果。
- 1. 导入所需的模块和库
from sklearn.neighbors import KNeighborsClassifier # 导入KNN分类模型的类
from sklearn.datasets import load_digits # 导入 sklearn的内置数据集中的手写数字数据集
from sklearn.model_selection import train_test_split # 导入切分训练集和测试集的方法- 2. 探索数据集
data = load_digits()datadata 数据集返回值 :
txt{'data': array([[ 0., 0., 5., ..., 0., 0., 0.], [ 0., 0., 0., ..., 10., 0., 0.], [ 0., 0., 0., ..., 16., 9., 0.], ..., [ 0., 0., 1., ..., 6., 0., 0.], [ 0., 0., 2., ..., 12., 0., 0.], [ 0., 0., 10., ..., 12., 1., 0.]]), 'target': array([0, 1, 2, ..., 8, 9, 8]), 'frame': None, 'feature_names': ['pixel_0_0', 'pixel_0_1', 'pixel_0_2', 'pixel_0_3', 'pixel_0_4', 'pixel_0_5', 'pixel_0_6', 'pixel_0_7', 'pixel_1_0', 'pixel_1_1', 'pixel_1_2', 'pixel_1_3', 'pixel_1_4', 'pixel_1_5', 'pixel_1_6', 'pixel_1_7', 'pixel_2_0', 'pixel_2_1', 'pixel_2_2', 'pixel_2_3', 'pixel_2_4', 'pixel_2_5', 'pixel_2_6', 'pixel_2_7', 'pixel_3_0', 'pixel_3_1', 'pixel_3_2', 'pixel_3_3', 'pixel_3_4', 'pixel_3_5', 'pixel_3_6', 'pixel_3_7', 'pixel_4_0', 'pixel_4_1', 'pixel_4_2', 'pixel_4_3', 'pixel_4_4', 'pixel_4_5', 'pixel_4_6', 'pixel_4_7', 'pixel_5_0', 'pixel_5_1', 'pixel_5_2', 'pixel_5_3', 'pixel_5_4', 'pixel_5_5', 'pixel_5_6', 'pixel_5_7', 'pixel_6_0', 'pixel_6_1', 'pixel_6_2', 'pixel_6_3', 'pixel_6_4', 'pixel_6_5', 'pixel_6_6', 'pixel_6_7', 'pixel_7_0', 'pixel_7_1', 'pixel_7_2', 'pixel_7_3', 'pixel_7_4', 'pixel_7_5', 'pixel_7_6', 'pixel_7_7'], 'target_names': array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]), 'images': array([[[ 0., 0., 5., ..., 1., 0., 0.], [ 0., 0., 13., ..., 15., 5., 0.], [ 0., 3., 15., ..., 11., 8., 0.], ..., [ 0., 4., 11., ..., 12., 7., 0.], [ 0., 2., 14., ..., 12., 0., 0.], [ 0., 0., 6., ..., 0., 0., 0.]], [[ 0., 0., 0., ..., 5., 0., 0.], [ 0., 0., 0., ..., 9., 0., 0.], [ 0., 0., 3., ..., 6., 0., 0.], ..., [ 0., 0., 1., ..., 6., 0., 0.], [ 0., 0., 1., ..., 6., 0., 0.], [ 0., 0., 0., ..., 10., 0., 0.]], [[ 0., 0., 0., ..., 12., 0., 0.], [ 0., 0., 3., ..., 14., 0., 0.], [ 0., 0., 8., ..., 16., 0., 0.], ..., [ 0., 9., 16., ..., 0., 0., 0.], [ 0., 3., 13., ..., 11., 5., 0.], [ 0., 0., 0., ..., 16., 9., 0.]], ..., [[ 0., 0., 1., ..., 1., 0., 0.], [ 0., 0., 13., ..., 2., 1., 0.], [ 0., 0., 16., ..., 16., 5., 0.], ..., [ 0., 0., 16., ..., 15., 0., 0.], [ 0., 0., 15., ..., 16., 0., 0.], [ 0., 0., 2., ..., 6., 0., 0.]], [[ 0., 0., 2., ..., 0., 0., 0.], [ 0., 0., 14., ..., 15., 1., 0.], [ 0., 4., 16., ..., 16., 7., 0.], ..., [ 0., 0., 0., ..., 16., 2., 0.], [ 0., 0., 4., ..., 16., 2., 0.], [ 0., 0., 5., ..., 12., 0., 0.]], [[ 0., 0., 10., ..., 1., 0., 0.], [ 0., 2., 16., ..., 1., 0., 0.], [ 0., 0., 15., ..., 15., 0., 0.], ..., [ 0., 4., 16., ..., 16., 6., 0.], [ 0., 8., 16., ..., 16., 8., 0.], [ 0., 1., 8., ..., 12., 1., 0.]]]), 'DESCR': ".. _digits_dataset:\n\nOptical recognition of handwritten digits dataset\n--------------------------------------------------\n\n**Data Set Characteristics:**\n\n:Number of Instances: 1797\n:Number of Attributes: 64\n:Attribute Information: 8x8 image of integer pixels in the range 0..16.\n:Missing Attribute Values: None\n:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)\n:Date: July; 1998\n\nThis is a copy of the test set of the UCI ML hand-written digits datasets\nhttps://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits\n\nThe data set contains images of hand-written digits: 10 classes where\neach class refers to a digit.\n\nPreprocessing programs made available by NIST were used to extract\nnormalized bitmaps of handwritten digits from a preprinted form. From a\ntotal of 43 people, 30 contributed to the training set and different 13\nto the test set. 32x32 bitmaps are divided into nonoverlapping blocks of\n4x4 and the number of on pixels are counted in each block. This generates\nan input matrix of 8x8 where each element is an integer in the range\n0..16. This reduces dimensionality and gives invariance to small\ndistortions.\n\nFor info on NIST preprocessing routines, see M. D. Garris, J. L. Blue, G.\nT. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C.\nL. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469,\n1994.\n\n.. dropdown:: References\n\n - C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their\n Applications to Handwritten Digit Recognition, MSc Thesis, Institute of\n Graduate Studies in Science and Engineering, Bogazici University.\n - E. Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika.\n - Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin.\n Linear dimensionalityreduction using relevance weighted LDA. School of\n Electrical and Electronic Engineering Nanyang Technological University.\n 2005.\n - Claudio Gentile. A New Approximate Maximal Margin Classification\n Algorithm. NIPS. 2000.\n"}
data 是一个字典的形式,我们可以使用 按键取值的方式取我们需要的数据
X 特征矩阵:
X = data.data #特征矩阵
X返回结果:
array([[ 0., 0., 5., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 10., 0., 0.],
[ 0., 0., 0., ..., 16., 9., 0.],
...,
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 2., ..., 12., 0., 0.],
[ 0., 0., 10., ..., 12., 1., 0.]])y 标签数组 :
y = data.target #标签数组
y返回结果:
array([0, 1, 2, ..., 8, 9, 8])# 如果数据是一张表,应该长这样
import pandas as pd
pd.DataFrame(X,columns=data.feature_names) # feature_names 有特征名,我们可以作为列名| pixel_0_0 | pixel_0_1 | pixel_0_2 | pixel_0_3 | pixel_0_4 | pixel_0_5 | pixel_0_6 | pixel_0_7 | pixel_1_0 | pixel_1_1 | ... | pixel_6_6 | pixel_6_7 | pixel_7_0 | pixel_7_1 | pixel_7_2 | pixel_7_3 | pixel_7_4 | pixel_7_5 | pixel_7_6 | pixel_7_7 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 5.0 | 13.0 | 9.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 6.0 | 13.0 | 10.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 12.0 | 13.0 | 5.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 11.0 | 16.0 | 10.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 4.0 | 15.0 | 12.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 5.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3.0 | 11.0 | 16.0 | 9.0 | 0.0 |
| 3 | 0.0 | 0.0 | 7.0 | 15.0 | 13.0 | 1.0 | 0.0 | 0.0 | 0.0 | 8.0 | ... | 9.0 | 0.0 | 0.0 | 0.0 | 7.0 | 13.0 | 13.0 | 9.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 1.0 | 11.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 16.0 | 4.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1792 | 0.0 | 0.0 | 4.0 | 10.0 | 13.0 | 6.0 | 0.0 | 0.0 | 0.0 | 1.0 | ... | 4.0 | 0.0 | 0.0 | 0.0 | 2.0 | 14.0 | 15.0 | 9.0 | 0.0 | 0.0 |
| 1793 | 0.0 | 0.0 | 6.0 | 16.0 | 13.0 | 11.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 1.0 | 0.0 | 0.0 | 0.0 | 6.0 | 16.0 | 14.0 | 6.0 | 0.0 | 0.0 |
| 1794 | 0.0 | 0.0 | 1.0 | 11.0 | 15.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 9.0 | 13.0 | 6.0 | 0.0 | 0.0 |
| 1795 | 0.0 | 0.0 | 2.0 | 10.0 | 7.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 2.0 | 0.0 | 0.0 | 0.0 | 5.0 | 12.0 | 16.0 | 12.0 | 0.0 | 0.0 |
| 1796 | 0.0 | 0.0 | 10.0 | 14.0 | 8.0 | 1.0 | 0.0 | 0.0 | 0.0 | 2.0 | ... | 8.0 | 0.0 | 0.0 | 1.0 | 8.0 | 12.0 | 14.0 | 12.0 | 1.0 | 0.0 |
1797 rows × 64 columns
探索标签类别 :
import numpy as np
np.unique(y) #探索标签类别返回结果:
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])即 标签的类别分别代表手写数字 0 - 9
- 3. 切分训练集和测试集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y # 特征和标签
,test_size=0.3 # 测试集所占的比例
,random_state=1) # 随机数种子查看切分结果:
Xtrain
"""
array([[ 0., 0., 2., ..., 3., 0., 0.],
[ 0., 0., 3., ..., 14., 4., 0.],
[ 0., 0., 6., ..., 8., 0., 0.],
...,
[ 0., 0., 7., ..., 13., 2., 0.],
[ 0., 0., 0., ..., 16., 1., 0.],
[ 0., 0., 8., ..., 0., 0., 0.]])
"""X.shape
# (1797, 64)Xtrain.shape
# (1257, 64)Xtest.shape
# (540, 64)Ytrain.shape
# (1257,)- 4. 建立模型&评估模型
clf = KNeighborsClassifier() # 实例化模型clf = clf.fit(Xtrain,Ytrain) # 使用训练集训练模型score = clf.score(Xtest,Ytest) # 看模型在新数据集(测试集)上的预测效果
score
# 0.9907407407407407
99%的预测准确率已经很高了,那么KNN模型在手写数字的数据集上还能不能表现的更好呢?这个就涉及到了 了。