🐍Python下一站
前言:
本笔记基于北大计算机教程陈斌老师的课程进行记录的个人笔记~
老师简介:
这个链接进入的视频所对应的合集《下一站Python》
一、Py排序
待更新~
二、递归的心
待更新~
三、语法知识
待更新~
四、实用模块
待更新~
压平嵌套循环:itertools模块
我们在做算法题的时候,经常会使用暴力💢的穷举法,就会经常出现下面的场景:
一方面为可怜的计算机考虑一下:一堆嵌套循环下去,内存和运行时长都爆炸了...
即使不为计算机考虑吧,这么多循环看着不晕吗?
那么就有一个非常好的内置模块
itertools:
itertools模块中的函数和类都是以生成器方式实现的,这使得它们在处理大规模数据集时具有较高的效率。相比于传统的迭代方式,使用itertools可以减少内存占用,提高程序运行速度。生成器是一种特殊的迭代器,它可以在需要时生成数据,而不是一次性生成所有数据。这使得生成器在处理大规模数据集时,能够有效地节省内存空间。
例题一:求100以内的所有勾股数
勾股数嘛,勾股三角形,比如三个边分别是 i , j ,k 。
那么如果满足
i*i + j*j = k*k那么不就形成了一组勾股数了吗
拿我们之前的惯用思维,穷举法把它干掉就是如下代码:
python# 100以内的勾股数 i*i+j*j==k*k (0<i,j,k<100) for i in range(1, 100): for j in range(1, 100): for k in range(1, 100): if i * i + j * j == k * k: print(i, j, k)
向上面这种三重循环在离散数学里叫
笛卡尔积笛卡尔积:我有两个集合,里面的元素分别进行一 一的组合 --> 这就相当于两重循环
from itertools import product
product(*iterables,repeat=1)若干个容器做笛卡尔积:
product('ABCD','xy')-->Ax Ay Bx By Cx Cy Dx Dy- ps : 这样就是上面传入的左右两个序列里面的元素分别进行 一 一的组合
容器做自身笛卡尔积:
product(range(2),repeat=3)-->000 001 010 011 100 101 111ps:
range(2)生成的就是 0 1 的序列嘛
repeat = 3就是 相当于我们之前做三重循环的意思那么就会有 2的三次方个结果,也就是8个结果
那么我们使用笛卡尔积来改写刚刚那个程序的话:
python# 使用笛卡尔积改写程序 from itertools import product for i, j, k in product(range(1, 100), repeat=3): if i * i + j * j == k * k: print(i, j, k)这样三重循环就变成一重了~
在运行上面的程序我们还会发现问题:会生成
3 4 5,4 3 5...其实我们认为这是同一组勾股数,那我们怎么找出不重复的勾股数?
例题二:求100以内不重复的勾股数
如(3,4,5)、(3,5,4)、(4,3,5)、(4,5,3)(5,4,3)、(5,3,4)我们算一组勾股数
那么我们可以使得生成的序列都是单调递增的就可以解决这个问题
比如上面那些组合,变成单调递增的话就只有 3 - 4 - 5 这样了
那么就可以把代码修改成:
python# 100以内不重复的勾股数 # 不能排除 i==j,j==k,i==k的可能性 for i in range(1, 100): for j in range(i, 100): for k in range(j, 100): if i * i + j * j == k * k: print(i, j, k)这样就可以让刚刚重复的勾股数只留下单调递增的
上面这种叫
元素可以重复的组合因为我们不能排除
i==j,j==k,i==k的可能性元素可重复的组合:
from itertools import combinations_with_replacementcombinations_with_replacement(iterable,r)- 容器取r个元素,元素可以重复的组合
combinations_with_replacement('ABC',2)-->AA AB AC BB BC CC- ps : 这样就是在 'ABC' 这个序列中取两个元素,使其组成可重复的组合
那么用
combinations_with_replacement来改写程序就是如下:python# 使用 combinations_with_replacement 来改写程序 # 不能排除 i==j,j==k,i==k的可能性 from itertools import combinations_with_replacement for i, j, k in combinations_with_replacement(range(1, 100), 3): if i * i + j * j == k * k: print(i, j, k)
例题三:砝码称不出的重量
- 有10个不同重量的砝码
- 任意取3个组合,请问在 [a,b]重量区间,哪些重量无法覆盖?
正常代码编写:
python# 重量组合问题 wlist = [5, 2, 3, 4, 5, 5, 6, 9, 12, 10] # 存有10个不同重量的列表 n = len(wlist) # n记录列表长度 10 a, b = 10, 30 # a,b即为重量区间 [a,b] wset = set(range(a, b + 1)) # 根据区间a,b生成 重量区间set 范围[a,b] # 题目任取"3个重量组合",设为i,j,k,即对应下面的三重循环 for i in range(n): for j in range(i + 1, n): # 从i+1开始,就形成j比i大 for k in range(j + 1, n): # # 从j+1开始,就形成k比j大. # 那么取到的组合肯定就是单调递增的ijk组合,就不会出现重复的索引 # 遍历的i,j,k是索引,根据索引在前面的列表取值,计算取到组合的总重量 total = wlist[i] + wlist[j] + wlist[k] # 取到的组合算出的总重量在[a,b]set内就可以集合删掉这个重量, # 删到循环结束后还留在set内就是“称不出的” if total in wset: wset.remove(total) print(wset)输出结果:
text{29, 30}
上面这种情景叫
元素不重复的组合即砝码重量不可取重复索引的,索引是不重复的,值是有可能重复的 索引为 0,4,5的对应的值都是5
元素不重复的组合:
from itemtools import combinationscombinations(iterable,r)- 容器取r个不重复元素的组合
combinations('ABCD',2)-->AB AC AD BC BD CDcombinations(range(4),3)-->012 013 023 123- ps : 有没有发现这种情景其实就是我们数学"排列组合"中学的 C几几 的那种
- 看上面的例子 一 :'ABCD' 中 选两个出来组合 ,不就是 C42么,那不就是 6种
- 上面的例子 二 :range(4) 中 选三个出来组合,不就是 C43 ,出来的结果不就是 4种
代码改进:
python# 重量组合问题 from itertools import combinations wlist = [5, 2, 3, 4, 5, 5, 6, 9, 12, 10] # 存有10个不同重量的列表 n = len(wlist) # n记录列表长度 10 a, b = 10, 30 # a,b即为重量区间 [a,b] wset = set(range(a, b + 1)) # 根据区间a,b生成 重量区间set 范围[a,b] for wi, wj, wk in combinations(wlist, 3): # 对前面的wlist任取三个出来组合 total = wi + wj + wk if total in wset: wset.remove(total) print(wset)输出结果:
text{29, 30}
最后来解决一道数学谜题:
上述算式中,每一个字母都是一个变量,可以存储一个数字,求出满足这个算式的变量对应数字
使用我们最熟悉的穷举法来编写代码如下:
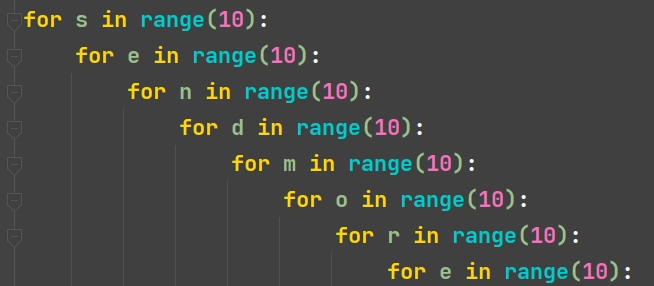
python# SEND MORE MONEY 数学谜题 # 枚举策略 (穷举法) import time # 导入时间模块计算程序运行花费的时间 start = time.time() # 记录程序开始的时间戳 for s in range(10): for e in range(10): for n in range(10): for d in range(10): for m in range(10): for o in range(10): for r in range(10): for y in range(10): # 放在一个列表里面去重,如果去重后的长度与原长度相同,说明没有重复元素 if len(set([s, e, n, d, m, o, r, y])) == 8: # 无重复,验证 if (s * 1000 + e * 100 + n * 10 + d) + \ (m * 1000 + o * 100 + r * 100 + e) == \ (m * 10000 + o * 1000 + n * 100 + e * 10 + y): # 这种样式的 f格式化是特殊的样式,常用于调试 # 这种语法不仅会打印出变量的值,还会打印出变量名和等号,因为=被包含在花括号中。 print(f"{s=},{e=},{n=},{d=},{m=},{o=},{r=},{y=}") end = time.time() # 记录程序结束的时间戳 print(f"总共用时:{end-start}秒") # end时间戳减去start时间戳就是程序花费时长输出结果:
texts=2,e=8,n=1,d=7,m=0,o=3,r=6,y=5 s=2,e=8,n=1,d=9,m=0,o=3,r=6,y=7 s=3,e=7,n=1,d=2,m=0,o=4,r=6,y=9 s=3,e=7,n=1,d=9,m=0,o=4,r=5,y=6 s=3,e=8,n=2,d=1,m=0,o=4,r=6,y=9 s=3,e=8,n=2,d=9,m=0,o=4,r=5,y=7 s=5,e=7,n=3,d=1,m=0,o=6,r=4,y=8 s=5,e=7,n=3,d=2,m=0,o=6,r=4,y=9 s=5,e=8,n=4,d=9,m=0,o=6,r=3,y=7 s=6,e=4,n=1,d=5,m=0,o=7,r=3,y=9 s=6,e=4,n=1,d=9,m=0,o=7,r=2,y=3 s=6,e=5,n=2,d=4,m=0,o=7,r=3,y=9 s=6,e=8,n=5,d=1,m=0,o=7,r=3,y=9 s=6,e=8,n=5,d=3,m=0,o=7,r=2,y=1 s=7,e=3,n=1,d=6,m=0,o=8,r=2,y=9 s=7,e=4,n=2,d=9,m=0,o=8,r=1,y=3 s=7,e=5,n=3,d=1,m=0,o=8,r=2,y=6 s=7,e=5,n=3,d=4,m=0,o=8,r=2,y=9 s=7,e=5,n=3,d=9,m=0,o=8,r=1,y=4 s=7,e=6,n=4,d=3,m=0,o=8,r=2,y=9 s=7,e=6,n=4,d=9,m=0,o=8,r=1,y=5 s=8,e=3,n=2,d=4,m=0,o=9,r=1,y=7 s=8,e=4,n=3,d=2,m=0,o=9,r=1,y=6 s=8,e=5,n=4,d=2,m=0,o=9,r=1,y=7 s=9,e=5,n=6,d=7,m=1,o=0,r=8,y=2 总共用时:35.36414575576782秒💢都别说这循环嵌套得....,而且用计算机还得几十秒,实在是太浪费了

上面这种情景其实是
排列没错,就是数学
排列组合里面的排列,也就是那个 A几几排列:
from itertools import permutations
permutations(iterable,r=None)可迭代对象的长度为 r 的排列
permutations('ABCD',2)-->AB AC AD BA BC BD CA CB CD DA DB DC可迭代对象的全排列 ( 不指定长度r ),每个元素都出现
permutations(range(3))-->012 021 102 120 201 210ps : 第一个例子:在序列 'ABCD' 里选两个出来进行排列,即
A42,所以12种情况第二个例子:对 range(3) (一个0-2,三个元素) 进行全排列,即
A33,也是3!,6种情况
改进代码:
python# 改进代码 import time # 导入时间模块计算程序运行花费的时间 from itertools import permutations start = time.time() # 记录程序开始的时间戳 for s, e, n, d, m, o, r, y in permutations(range(10), 8): if (s * 1000 + e * 100 + n * 10 + d) + \ (m * 1000 + o * 100 + r * 100 + e) == \ (m * 10000 + o * 1000 + n * 100 + e * 10 + y): print(f"{s=},{e=},{n=},{d=},{m=},{o=},{r=},{y=}") end = time.time() # 记录程序结束的时间戳 print(f"总共用时:{end-start}秒") # end时间戳减去start时间戳就是程序花费时长输出结果:
texts=2,e=8,n=1,d=7,m=0,o=3,r=6,y=5 s=2,e=8,n=1,d=9,m=0,o=3,r=6,y=7 s=3,e=7,n=1,d=2,m=0,o=4,r=6,y=9 s=3,e=7,n=1,d=9,m=0,o=4,r=5,y=6 s=3,e=8,n=2,d=1,m=0,o=4,r=6,y=9 s=3,e=8,n=2,d=9,m=0,o=4,r=5,y=7 s=5,e=7,n=3,d=1,m=0,o=6,r=4,y=8 s=5,e=7,n=3,d=2,m=0,o=6,r=4,y=9 s=5,e=8,n=4,d=9,m=0,o=6,r=3,y=7 s=6,e=4,n=1,d=5,m=0,o=7,r=3,y=9 s=6,e=4,n=1,d=9,m=0,o=7,r=2,y=3 s=6,e=5,n=2,d=4,m=0,o=7,r=3,y=9 s=6,e=8,n=5,d=1,m=0,o=7,r=3,y=9 s=6,e=8,n=5,d=3,m=0,o=7,r=2,y=1 s=7,e=3,n=1,d=6,m=0,o=8,r=2,y=9 s=7,e=4,n=2,d=9,m=0,o=8,r=1,y=3 s=7,e=5,n=3,d=1,m=0,o=8,r=2,y=6 s=7,e=5,n=3,d=4,m=0,o=8,r=2,y=9 s=7,e=5,n=3,d=9,m=0,o=8,r=1,y=4 s=7,e=6,n=4,d=3,m=0,o=8,r=2,y=9 s=7,e=6,n=4,d=9,m=0,o=8,r=1,y=5 s=8,e=3,n=2,d=4,m=0,o=9,r=1,y=7 s=8,e=4,n=3,d=2,m=0,o=9,r=1,y=6 s=8,e=5,n=4,d=2,m=0,o=9,r=1,y=7 s=9,e=5,n=6,d=7,m=1,o=0,r=8,y=2 总共用时:0.963430643081665秒可见代码量和用时都大幅度降低了!!!
然后发现运行结果,前面全是
m=0的情况,也就是算出来的那个MONEY的首位是 0即
MONEY是一个四位数 。 只有最后一组是m=1的。所以题目应该还得有一个筛选条件,就是
m!=0的情况,这样得到的解就是唯一的了
五、ChatGPT
待更新~