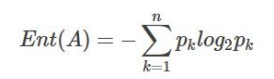基于 ML 的 CV
一、ML 的数学基础
对一些需要用到的概念作简单描述,暂时不作深入了解
1. 向量
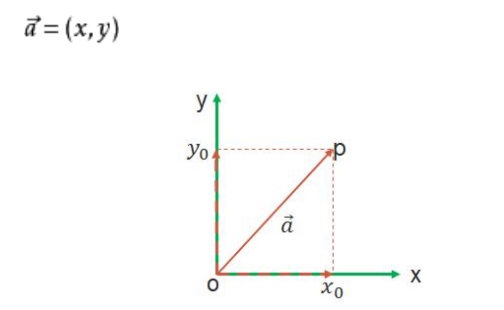
向量可以简单理解为一个 的量。
在二维空间中,向量通常表示为
(x,y),其中
x和y分别表示向量在x轴和y轴上的分量。如下图所示:
向量在机器学习中有着广泛的应用,尤其是在表示数据、计算相似度、优化算法等方面。
数据表示:在机器学习中,数据通常被表示为向量。
例如,一张图片可以被表示为一个高维向量,每个维度代表一个像素的灰度值或颜色值。
相似度计算:向量的点积可以用来计算两个数据点之间的相似度。
点积越大,表示两个向量越相似。
优化算法:在梯度下降等优化算法中,梯度本身就是一个向量,表示函数在某一点的变化方向和速率。
2. 线性变换
线性变换 : 一个向量空间到另一个向量空间的映射
且满足以下两个性质:
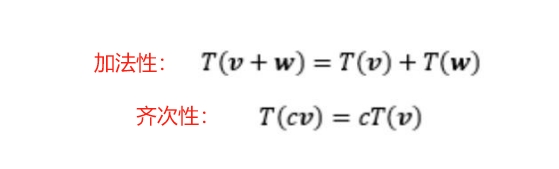
这两个性质保证了线性变换在向量空间中的 “线性” 特性,
即变换后的向量空间仍然保持线性结构。
3. 矩阵
矩阵可以简单理解为一个由数字排列成的矩形表格,
通常用大写字母表示,如
A、B等。
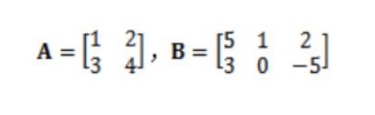
- 矩阵加减法
两个矩阵相加减,要求它们的维度相同。
结果矩阵的每个元素为两个矩阵对应元素的和或差。
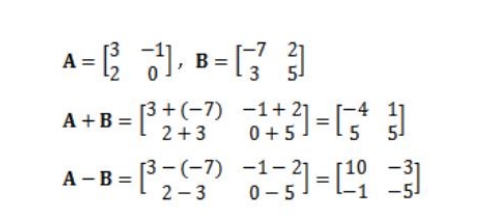
- 矩阵乘法
两个矩阵
A和B相乘,要求A的列数等于B的行数。结果矩阵的每个元素为
A的行向量与B的列向量的点积。注意:矩阵乘法跟乘的顺序密切相关(可见下图)
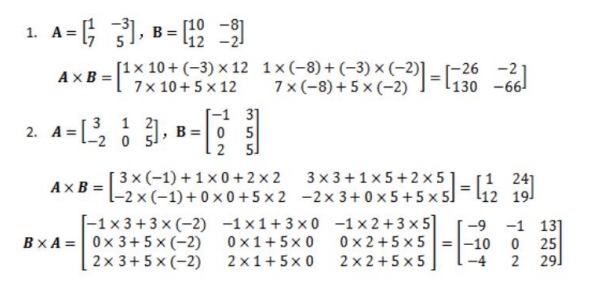
- 单位矩阵
单位矩阵是一个
n × n的方阵,对角线上的元素为 1,其余元素为 0。单位矩阵在矩阵乘法中的作用类似于数字 1。

如果
A是n×n矩阵,I是单位矩阵,则AI= A,IA = A
- 逆矩阵
对于一个
n × n的方阵A, 如果存在:

也就是 : 这个矩阵可以和原矩阵相乘,无论什么顺序,都可以得到单位矩阵
那么则称这个矩阵就是原矩阵的逆矩阵

逆矩阵的存在条件是 : 矩阵的行列式不为零

其实也很好理解,我们看上面逆矩阵的运算公式,分母位置的值就是矩阵的行列式的值,
分母总不能为 0 吧,那么也就有了 -- 逆矩阵的存在条件是 : 矩阵的行列式不为零
- 奇异矩阵
当一个矩阵没有逆矩阵的时候,称该矩阵为 奇异矩阵 。
当且仅当一个矩阵的行列式为零时,该矩阵是奇异矩阵。

- 矩阵的转置
简单地说,矩阵的转置就是行列互换
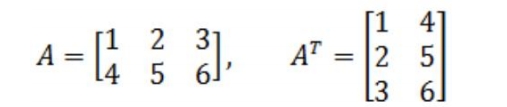
转置运算特性:
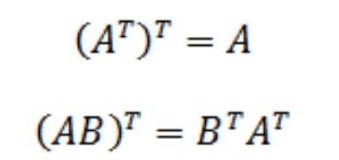
注意上面第二条公式,后面的乘法顺序是改变了的,这是很关键的点 !
- 对称矩阵
如果一个矩阵转置后等于原矩阵,那么这个矩阵称为对称矩阵。
一个矩阵转置和这个矩阵的乘积就是一个对称矩阵。
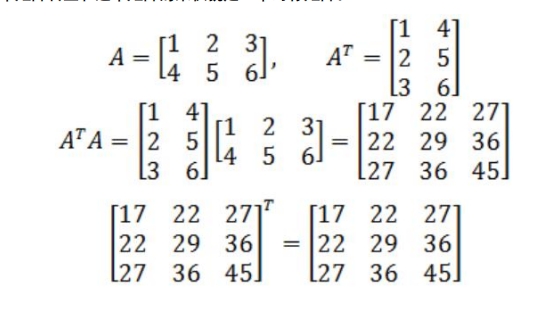
4. 欧式变换
欧式变换由 两部分组成

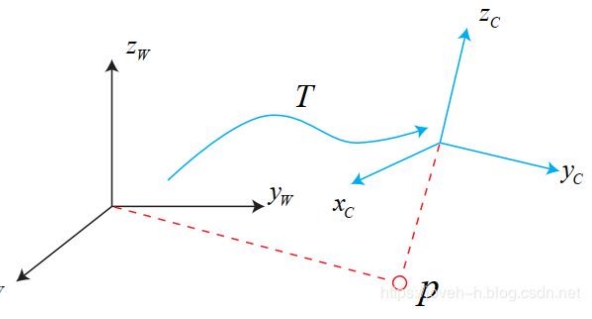
其实也很好理解,我们不要想成 矩阵 或者 向量那么复杂,
我们用我们最熟悉的例子 : 一次函数的图像
表达式是 :
y = kx + b是不是跟上面很像,
当我们调整
k的时候,在函数图像上就实现了当我们调整
b的时候,在函数图像上就实现了
5. 齐次坐标
齐次坐标 用于简化欧式变换的表示和计算。
齐次坐标 通过增加一个额外的维度来表示点或向量,从而将旋转和平移统一表示为矩阵乘法。
- 齐次坐标的定义 : 齐次坐标是用
N+1维向量来表示N维空间中的点 。
例如:二维空间中的点
(x,y)可以用齐次坐标表示为(x,y,w), 其中w是 一个额外的坐标
从齐次坐标到笛卡尔坐标:齐次坐标
(x,y,w)对应的笛卡尔坐标为:( x/w , y/w )通常,我们取
w = 1, 这样齐次坐标(x,y,1)对应的笛卡尔坐标为(x,y)无穷远点:当
w = 0时 ,齐次坐标(x,y,0)表示一个无穷远点,对应笛卡尔坐标中的(∞,∞)
- 优点
- 统一表示:齐次坐标可以将旋转、平移、缩放等变换统一表示为矩阵乘法,简化了计算。
- 处理无穷远点:齐次坐标可以方便地表示和处理无穷远点,这在投影几何中非常重要。
6. 导数&偏导数
导数(微分):是代表 ,是 ,
同时曲线的极大(小)值点也可以使用导数来判断,即 。
偏导数:是指在 的情况下,对其每个变量进行求导,
求导时,把 ,
物理意义就是查看这一个变量在其他情况不变的情况下对函数的影响程度。
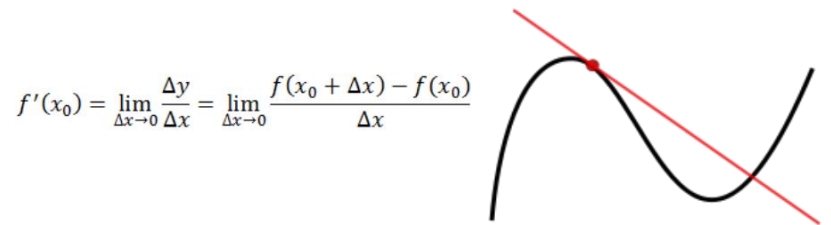

7. 梯度
梯度 : 梯度的本意是一个 ,表示某一函数在该点处的方向导数沿着该方向取得最大
值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)
简而言之,对多元函数的各个自变量求偏导数,
并把求得的这些偏导数写成向量形式,就是梯度。
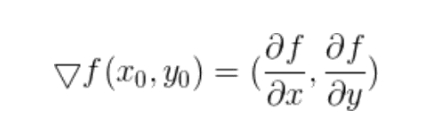
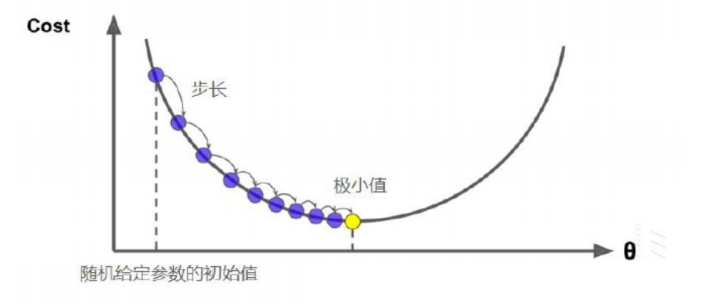
- 梯度下降法
该方法最普通的做法是:在已知 的情况下,按 ,
并按事先给定好的 ,对参数进行调整。
按如上方法对参数做出多次调整之后,函数就会逼近一个极小值。
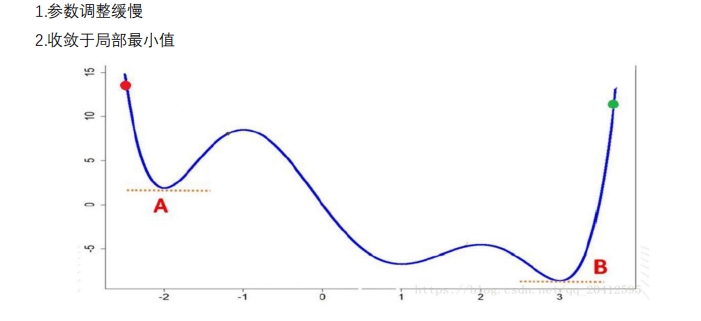
- 缺点
8. 概率学基础
Machine Learning与Traditional statistical analyses的一些区别,主要在关注主体和验证性作区分。
前者不关心模型的复杂度有多么的高,仅仅要求模型有良好的泛化性以及准确性。
而后者在模型本身有一定的要求 —— 不可过于复杂。
- 事件关系维恩图
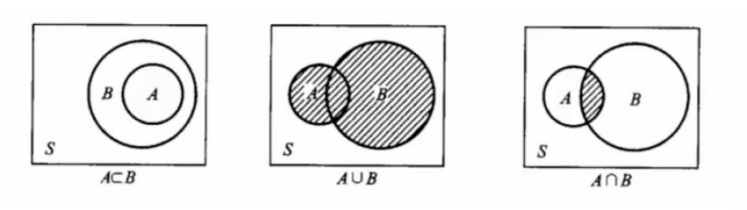
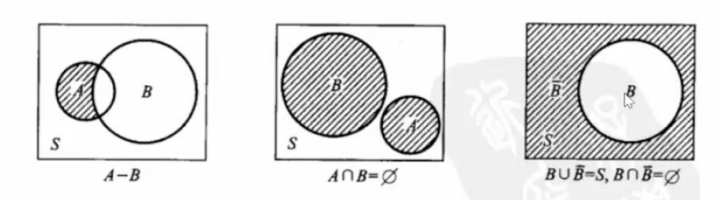
- 事件运算定律
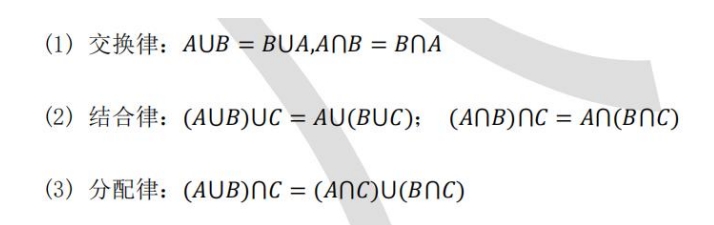
概率的基本概念
概率:事件发生的可能性大小的度量,其严格定义如下:
概率
P(g)为定义在事件集合上的满足下面 2 个条件的函数:• 1) 对任何事件A,
P(A) >= 0• 2) 对必然事件B,
P(B) = 1概率的基本性质 :
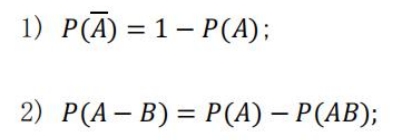
古典型概率 : 实验的所有结果只有有限个,且每个结果发生的 ,其概率计算公式:

独立性
设 A,B 为随机事件,若同时发生的概率等于各自发生的概率的乘积,则A,B 相互独立。
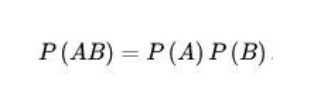
- 离散
离散就是不连续 ...
在函数图像上解释就很直观 :
连续:一笔画一条线不断开
离散:一个一个坐标点
在后面将要讲到的数字图像里 :
一个图像在我们肉眼中是连续的
但是在计算机里就是一个矩阵,然后矩阵是一个一个数值,这就是离散的了
- 数学期望
数学期望(均值):表示一件事平均发生的概率,记为
E(x),
E(x) = x1p1 + x2p2 + ... + xnpn。 或者 :
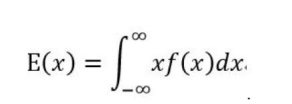
- 方差
方差 : 用来刻画 随机变量
x和数学期望E(x)之间的 ,记做D(x)。
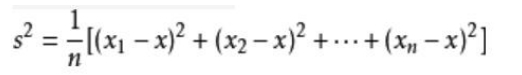
其次:

- 标准差
标准差(均方差):标准差是 。标准差能反映一个数据集的离散程度。
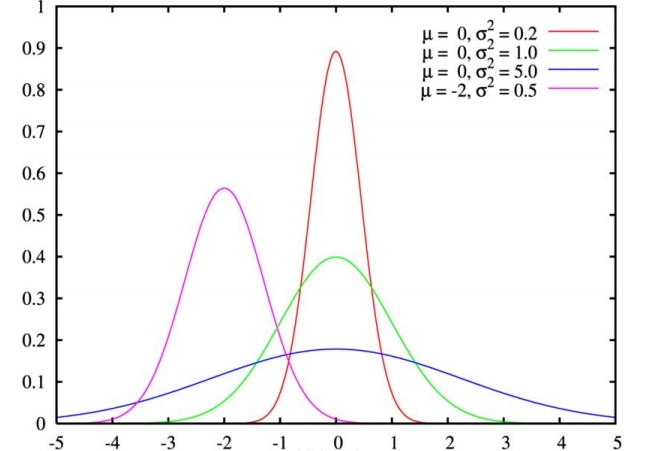
- 正态分布(高斯分布)
正态分布:若随机变量X服从一个数学期望为
μ、方差为σ^2的正态分布,记为N(μ,σ^2)。μ 决定了其 ,其 标准差 σ 决定了 。
- 标准正态分布:当
μ = 0,σ = 1时的正态分布是标准正态分布
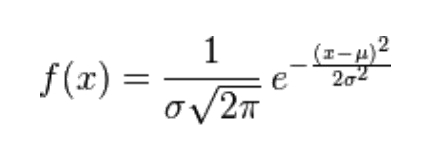
9. 熵
熵
entropy:在物理学上,是 。
系统越有序,熵值越低 ;
系统越混乱或者分散,熵值越高 。
信息理论:
1、当系统的有序状态一致时,数据越集中的地方熵值越小,
数据越分散的地方熵值越大。这是从信息的完整性上进行的描述。
2、当数据量一致时,系统越有序,熵值越低;
系统越混乱或者分散,熵值越高。这是从信息的有序性上进行的描述。
简而言之:
假如事件A的分类划分是
(A1,A2,…,An),每部分发生的概率是(p1,p2,…,pn),那信息熵定义为公式如下: