📝 Python_Note
附录:
1. 安装 anaconda
通过网盘分享的文件:Anaconda3-2024.10-1-Windows-x86_64.exe
链接: https://pan.baidu.com/s/1niNxrTVIS02varuAlRvAVw?pwd=ccjc 提取码: ccjc
--来自百度网盘超级会员v6的分享2. 配置 Jupyter lab
- 注意:CMD安装第三方模块,注意一定要配置国内镜像源,不然很可能下载失败。
python -m pip install --upgrade pip
pip install jupyterlab- 安装时间一般需要2到5分钟,安装成功后使用以下命令即可进入:
jupyter lab注意:在
jupyter中进行操作时,不能关闭终端。因为一旦关闭终端,就会杀死进程,jupyter就会断开与本地服务器的链接,就无法进行其他操作了。
安装中文模块,使界面汉化, 如果进入了
jupyter可以 按ctrl + c退出终端任务后,使用以下命令安装汉化模块:
pip install jupyterlab-language-pack-zh-CN- 按照界面菜单栏以下选项设置汉化:

- 开启插件功能,安装第三方插件:
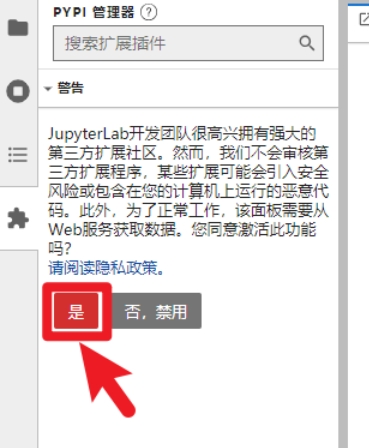
- 安装代码补全插件,此插件需要在 cmd 终端上安装
pip install jupyterlab-lsp
pip install -U jedi-language-server
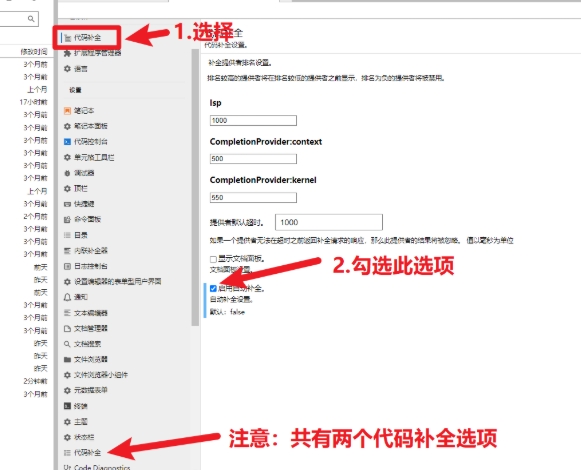
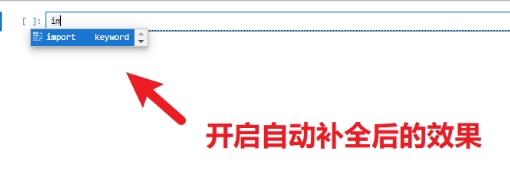
pip install python-lsp-server[all]- 设置自动代码提示:菜单栏点击设置 --> 设置编辑器 --> 代码补全 --> 勾选 “启用自动补全”。
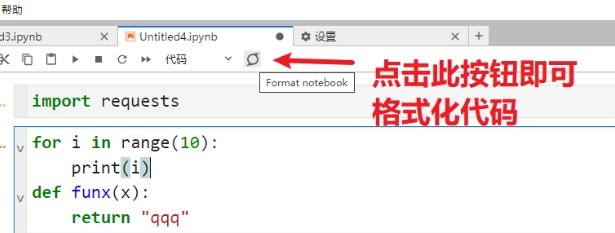
- 格式化代码插件 :
pip install jupyterlab_code_formatter
pip install autopep8
pip install black
pip install isort执行以上指令后,需要重启
jupyter lab终端服务
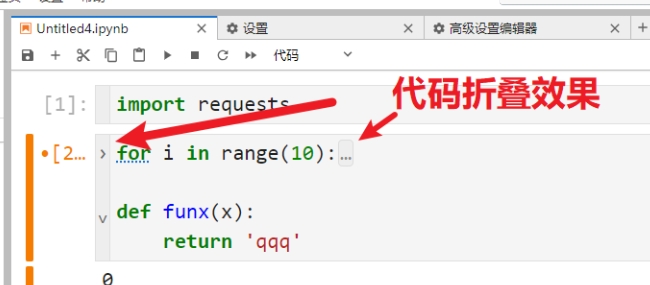
效果如下:
- 字体大小设置,可以在菜单栏选项中设置字体大小 :
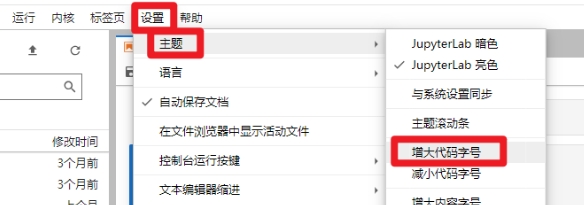
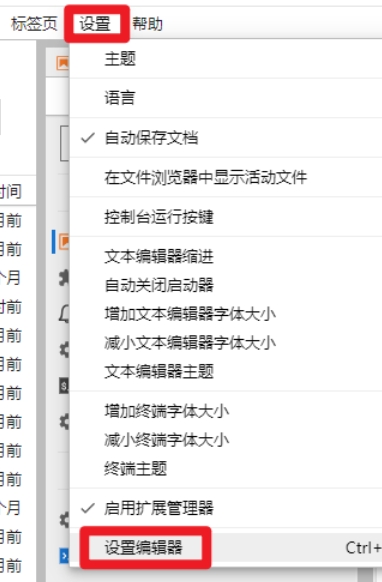
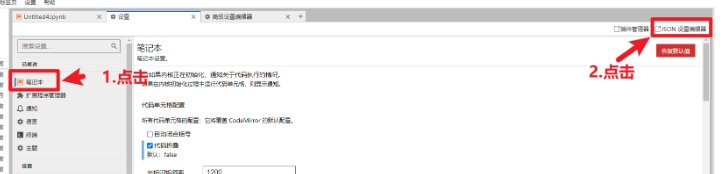
- 代码折叠功能配置:设置 --> 设置编辑器 --> 笔记本 --> JSON设置编辑器 --> 输入配置 --> 点击保存 --> 刷新页面生效
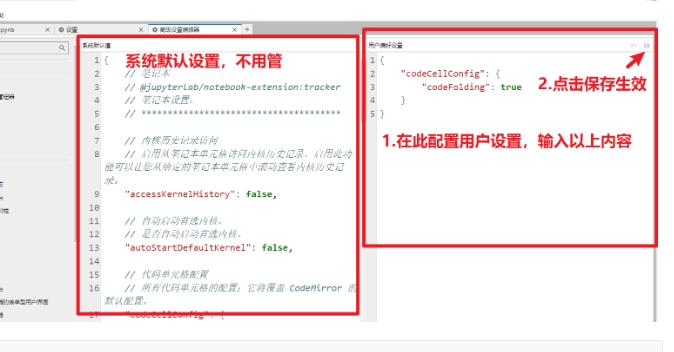
{
"codeCellConfig": {
"codeFolding": true
}
}
3. jupyter 基础
- 什么是cell?
- cell :一对
INOut会话被视作一个代码单元,称为cell - cell 行号前的
*, 表示代码正在运行
- cell :一对
Jupyter 支持两种模式 :
- 编辑模式(Enter)
- 命令模式下
回车Enter或鼠标双击cell进入编辑模式 - 可以操作cell内文本或代码,剪切/复制/粘贴移动等操作
- 命令模式下
- 命令模式(Esc)
- 按
Esc退出编辑,进入命令模式 - 可以操作cell单元本身进行剪切/复制/粘贴/移动等操作
- 按
快捷键操作
两种模式通用快捷键
Shift+Enter,执行本单元代码,并跳转到下一单元Ctrl+Enter,执行本单元代码,留在本单元
命令模式:按ESC进入
- Y :在命令模式下转入代码状态
- M :在命令模式下切换到 Markdown
- R :普通文本,运行不会输出结果
- L :为当前cell加上行号
- A:在该单元格的上方插入新单元格
- B:在该单元格的下方插入新单元格
- X:剪切选中的单元
- C:复制选中的单元
- V:粘贴到下方单元
- DD:删除选中的单元(敲两个D)
其他 (了解)
双击D:删除当前cellZ,回退- 快速跳转到首个cell,
Crtl+Home - 快速跳转到最后一个cell,
Crtl+End
编辑模式:按 Enter 进入
- 补全代码:变量、方法后跟
Tab键 - 为一行或多行代码添加/取消注释:
Ctrl+/(Mac:CMD+/)
- 补全代码:变量、方法后跟
其他 (了解):
- 多光标操作:
Ctrl键点击鼠标(Mac:CMD+点击鼠标) - 回退:
Ctrl+Z(Mac:CMD+Z) - 重做:
Ctrl+Y(Mac:CMD+Y)
- 多光标操作:
4. pip 使用
pip 是 Python 的包管理器。也是最常用的工具,熟练掌握 pip 指令有助于大幅提升开发速度。
- 查看帮助
pip -h
$ pip -h
Usage:
pip <command> [options]
Commands:
install Install packages.
download Download packages.
uninstall Uninstall packages.
freeze Output installed packages in requirements format.
inspect Inspect the python environment.
list List installed packages.
show Show information about installed packages.
check Verify installed packages have compatible dependencies.
config Manage local and global configuration.
search Search PyPI for packages.
cache Inspect and manage pip's wheel cache.
index Inspect information available from package indexes.
wheel Build wheels from your requirements.
hash Compute hashes of package archives.
completion A helper command used for command completion.
debug Show information useful for debugging.
help Show help for commands.- 安装指定包
pip install flask- 安装
requirements.txt文件列出的包 :
pip install -r requriements.txt- 安装 whl 文件
.whl文件,全称为wheel文件,是 Python 分发包的标准格式之一。它是一种预编译的二进制包,用于简化 Python 包的安装过程,使得安装更加快速和高效
pip install wheel
pip install xxxx.whl- 更新
pip install --upgrade 包名称- 如果要指定升级到某个版本,可以使用
pip install --upgrade 包名称==版本号
注意:
不要使用 pip install --upgrade pip 更新 pip 自身,否则会在更新 pip 的时候删除掉 pip,
然后出现 No module named pip 的情况 ,
可运行如下命令安装 pip : python -m ensurepip
如果要更新 pip 自身,可以使用如下命令: python -m pip install --upgrade pip
- 删除指定包
pip uninstall 包名- 删除
requriements.txt文件中列出的包
pip uninstall -r requriements.txt- 列出安装的所有包
pip list- 查看某一个包的具体信息
pip show 包名- 导出安装包列表
pip freeze > requirements.txt导出
pip所在环境中所安装的所有包,将其输出到requirements.txt文件中
5. pip 换源 (重要)
由于国内通过 pip 下载 python 包的速度真的很慢,
特别是下载包文件比较大的情况下经常会导致下载失败,
把默认的 PyPi 源切换化为国内源 tuna, douban, aliyun 从而可以加快 python 包的安装速度。
- pip 国内的一些镜像
- http://pypi.douban.com/simple 是豆瓣提供一个镜像源,软件够新,连接速度也很好。
- http://mirrors.aliyun.com/pypi/simple/ 阿里云的源
- https://pypi.tuna.tsinghua.edu.cn/simple 清华镜像源
window 配置
打开
C:盘,进入个人用户目录然后新建一个
pip文件夹进入文件夹,新建一个
pip.ini的文件如果没有齿轮形状,请先打开可以查看文件后缀名
然后用 记事本 或者是
notepad++打开这个文件,往里面写入
[global]
timeout = 6000
index-url = http://pypi.douban.com/simple
trusted-host = pypi.douban.com[global]
timeout = 6000
index-url = http://mirrors.aliyun.com/simple/
trusted-host = mirrors.aliyun.com[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn一、基础语法
print("Hello , welcome to irai's knowledge station ")1_1. 标识符
标识符(identifier)是指用来标识某个实体的一个符号,在不同的应用环境下有不同的含义。 在计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系。通俗点讲,标识符就是名字。
- 第一个字符必须是字母表中字母或下划线 _ 。
- 标识符的其他的部分有字母、数字和下划线组成。
- 标识符对大小写敏感。
注意:Python 解释器里面的符号都需要为英文状态的符号,中文的符号会被解释为字符串。
# 大小写敏感
A = 1
a = 3
print(A == a)
# False
print(A,a)
# 1,31_2. Python 中的保留字
保留字即关键字,我们不能把它们用作任何标识符名称。Python 的标准库提供了一个 keyword module,可以输出当前版本的所有关键字:
import keyword
print(keyword.kwlist)运行结果:
text['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']上述都是关键字,千万不要拿关键字来命名!! 哪怕加个下划线也行...
上面没列出的,比如内置的方法也不能用来命名,比如我见过
str = input()上面的语句的意思接收一个键盘输入的字符串,然后用变量str接收呗??
然后,后面用到 str强转 ,就是
str(), 比如a = str(123)电脑就傻了...,要不就报错,要不就运行框一直无反应....
前面都用str命名去了,就会导致这种低级错误
1_3. 注释
- 机器不执行注释内容。
- 注释一般用自然语言书写。
- 注释的写法。
单行注释和多行注释的方法: Python 中单行注释以 # 开头,可以单独一行进行注释,也可以在一行代码后进行注释,单行注释仅能注释当前行。 多行注释用三个单引号 ''' 注释掉的内容’'' 或者三个双引号 """ 注释掉的内容""" 将注释括起来,引号直接的内容可以包含换行等字符。通过将中间的内容转换为文档字符串达到注释的效果,在注释大段的代码块时较多使用。
# 这是独立一行的单行注释
num = 1 # 这是跟在一行代码后的单行注释
print(num)
# 我是多个单行注释,
# 我是多个单行注释,
# 我是多个单行注释,
# 我是多个单行注释,
# print("Hello World!")
"""
我是多行注释,
中间可以随意换行,
里面的代码也不会执行,
因为当作字符串解释了。
print("Hello World!")
"""1_4. 变量
- 变量就是一个可以重复使用的量,或者叫一个代号
- 在Python中,不需要先声明变量名及其类型,直接赋值就可以创建各种类型的变量。
- 变量的命名要遵循以下几条规则:
- 只能包含:数字、字母、下划线
- 下划线开头有特殊含义,不建议使用
- python大小写敏感
- 不能:以数字开头、包含空格;
- 不能使用python保留字、关键字、函数名
- 建议:简短却有描述性、使用小写字母
变量的命名要点
注意大小写
- python
# 注意大小写 a=1 A=2 print(a) # 1 print(A) # 2
不要用保留字
- python
import keyword print(keyword.kwlist) #...
驼峰命名法
- 大驼峰,名称以单词自动链接,每个单词的首字母大写
- 在python当中给类命名使用此办法
- eg: MyFristPet
- 小驼峰,类似大驼峰,但是第一个字母小写
- 在python当中给函数或者普通变量用这个办法:
- eg: myPet
- posix写法:
- 多个单词用下划线连接,单词都小写(推荐)
- 👍eg: my_pet
- 多个单词用下划线连接,单词都小写(推荐)
- 大驼峰,名称以单词自动链接,每个单词的首字母大写
变量的赋值
- 在 Python 中,变量就是变量,它没有固定的类型,我们所说的「类型」是变量当前所指向的内存中对象的类型。
- 一个变量可以重复赋值,后面的赋值会覆盖前面的赋值。
python#对单个变量的赋值 counter = 100 pi = 3.14 name = "Python" print (counter) # 100 print (pi) # 3.14 print (name) # Python # 对同一个变量多次赋值 a = 123 print(a) # 123 a = 'ABC' print(a) # ABC # 为多个变量赋值 a = b = c = "可以" print(a) # 可以 print(b) # 可以 print(c) # 可以 e , f, g ="你", "我", "他" print(e,f,g) # 你 我 他 # Python中两个变量的交换 a = 1 b = 2 a, b = b, a print(a, b) # 2 1变量的删除
- 如果你不小心用保留字做了变量名,导致代码报错,可以使用del方法直接删除
- 如果你不想要这个变量了,删不删其实都可以,你可以选择重新赋值,当然也可以删除
print = 1
print('hello') # TypeError: 'int' object is not callable
del print
print('hello') # hello二、基本数据类型
类型的作用:编程语言对数据的一种划分,数据从不同角度看有不同的含义。 程序设计语言不允许存在语法歧义,因此,需要明确说明数据的含义, 这就是“类型” 的作用。
Python中常用的数据类型有:
- 数字 (Numbers) 整数、浮点数、分数、复数等
- 布尔值 (Booleans) True 或 False
- 字符串 (Strings) Unicode 字符序列(不可变对象)
- 列表 (List) 有序的值可变的序列
- 元组 (Tuples) 有序的值的序列且不可改变
- 集合 (Sets) 无序的不含重复值的序列
- 字典 (Dictionaries) 无序的键值对的集合
类型判断:type(obj): 返回obj的类型
print(type(1)) # <class 'int'>
print(type(1.0)) # <class 'float'>
print(type(True)) # <class 'bool'>
print(type('1')) # <class 'str'>2_1. Bool 布尔类型
和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False。
在 Python 中,任何非零整数都是 True;0 是 False。
条件也可以是字符串或列表,实际上可以是任何序列,
所有长度不为零的是 True,空序列是False。
# 可以用Bool类型进行数值运算,False算0,True算1
print(False + True) # 1
print(False + False) # 0
print(bool(1)) # True
print(bool(100)) # True
print(bool("Hi!")) # 字符串 # True
print(bool(" ")) # 空格字符 # True
print(bool(0)) # False
print(bool("")) # 空字符串 # False
print(bool([])) # 空列表 # False
print(bool(None)) # 空值 # False2_2. Numbers 数值类型
Python中最常用的数值型就是:整数(int)和 浮点数(float)。
(1)整数 int Python 默认可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写 法一模一样,例如:1,100,-8080,0 等等。 在解释器中输入一个整数也会得到一个同样整数的输出:
print(type(100)) # <class 'int'>Python中的整数长度没有限制,通常是连续分配的内存空间
a = 1000000000000023598567902689034860483976
print(a)
# 1000000000000023598567902689034860483976(2)浮点数 float 浮点数也就是小数,浮点数可以用数学写法,如1.23,3.14,-9.01. 但是对于很大或很小的浮点数,就必须用科学记数法表示。
浮点数有精度上的限制,默认超过16 位就不再精确了:
num = 1.2345678901234567890
print(num)
# 1.1234567890123457科学计数法使用字母“e” 或者“E” 作为幂的符号,以10为基数
print(2.3e2) # 230.0
print(2.45E6) # 2450000.0
print(2.3*100)
# 229.99999999999997Note:
- 整数和浮点数在计算机内部存储的方式是不同的,整数运算结果永远是精确的,而浮点数运算则可能会有精度上的误差。
- 浮点数存在上界和下界,超过结果导致溢出。
- 由于存储有限,计算机不能精确显示无限小数,会产生误差。
- 另外计算机内部采用二进制,不是所有的十进制实数都可以用二进制数精确表示。
(3)类型转换
print(int(1.24)) # 1
print(int(1.89)) # 1【注意】将浮点型转换成整数时,小数点后面的数字都会砍掉,注意不是四舍五入。 如果想用四舍五入可以使用 round函数
print(round(1.23)) # 1
print(round(1.89)) # 2
# 默认保留0位小数(保留成整数),也可以使用第二个参数指定位数
print(round(1.89, 1)) # 1.9但是要注意,这可能不是我们数学上严格的四舍五入
- 当需要四舍五入到最近的整数时,如果小数部分恰好是0.5,
round()函数会四舍五入到最近的偶数整数。这被称为“银行家舍入法”(Banker's rounding),目的是减少四舍五入的偏差。
( 了解即可 ) 银行家舍入法(Banker's rounding),也称为偶数舍入法(round half to even),是一种舍入规则,旨在减少舍入误差的累积。在这种舍入方法中,当需要舍入的数字正好处于两个可能的舍入值的中间时(即小数部分为0.5),则舍入到最近的偶数整数。
银行家舍入法的意义:
减少系统性偏差:
- 在统计学中,如果总是将0.5舍入到最近的较大数,那么随着舍入次数的增加,结果会逐渐偏向较大的值,造成系统性偏差。银行家舍入法通过舍入到最近的偶数,减少了这种偏差。
统计上的公平性:
- 银行家舍入法确保了在多次舍入后,向上和向下舍入的次数大致相等,从而在统计上更加公平。
减少舍入误差:
- 在某些应用中,如金融计算,舍入误差的累积可能会导致显著的财务差异。银行家舍入法通过减少这种累积误差,提高了计算的准确性。
避免“四舍五入瘟疫”:
“四舍五入瘟疫”是指在多个数字相加后,由于四舍五入导致的误差累积,使得总和与预期不符。
银行家舍入法有助于减少这种现象。
银行家舍入法的示例:
- 对于数字 2.5,按照银行家舍入法,应该舍入到 2,因为 2 是偶数。
- 对于数字 3.5,按照银行家舍入法,应该舍入到 4,因为 4 是偶数。
print(round(0.5)) # 0
print(round(1.5)) # 2
print(round(2.5)) # 2
print(round(3.5)) # 4
print(round(2.125,2)) # 2.12如果
ndigits(第二个参数) 为负数,则四舍五入到小数点左边ndigits位。
# 四舍五入到整数左边
print(round(123.456, -1)) # 120.0
print(round(126.123, -1)) # 130.0四舍五入负数
pythonprint(round(-3.6)) # -4 print(round(-3.4)) # -3
# 将整型转换成浮点型
float(6) # 6.02_3. 字符串
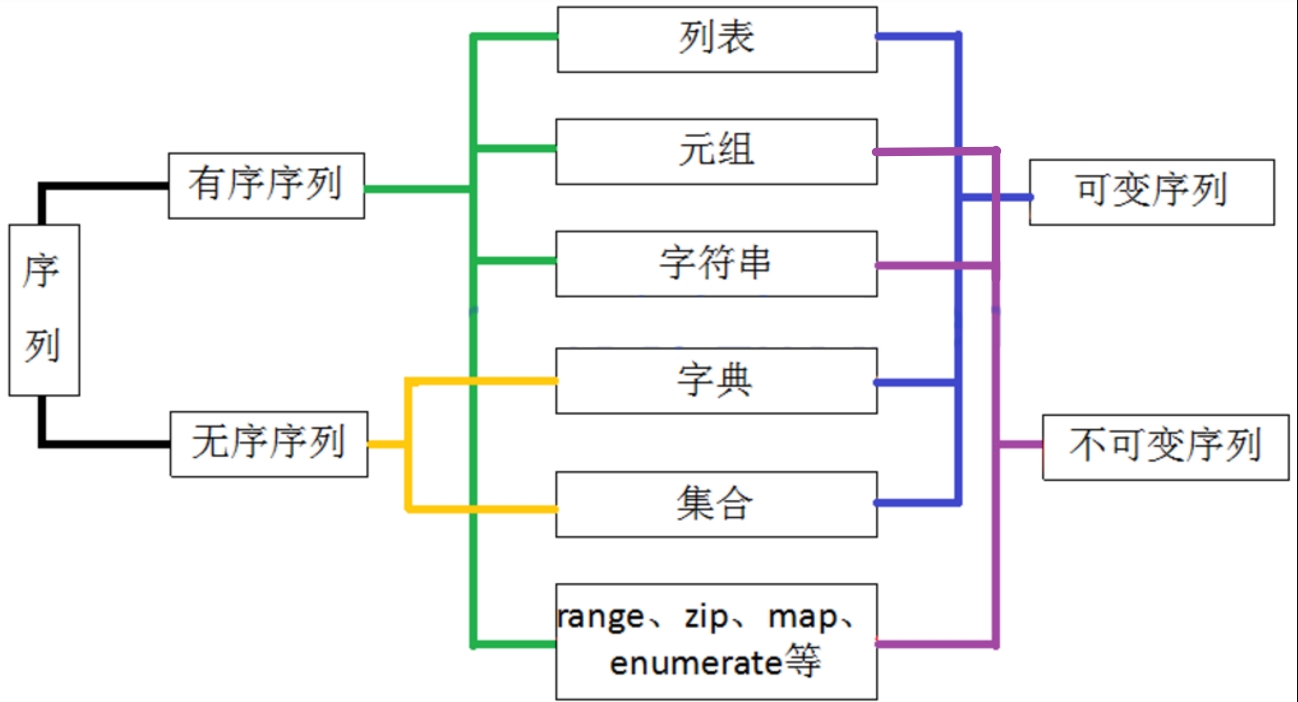
序列的概念
- 序列是一处存放多个值的连续内存空间。
- 序列的每一个值称为元素,每一个元素都会分配一个数字,这个数字成为索引(或位置)。
- 在Python中,序列结构的主要有字符串、列表、元组、字典、集合。(我们后面会陆续介绍)
- 字符串就是连续的字符序列,是计算机所能表示的一切字符的集合。
- 在Python中,字符串属于不可变序列。
- 通常使用单引号''、双引号""、或者三引号''' '''或""" """括起来。
- 这三种引号形式在语义上没有差别,只是在形式上有些差别。
- 单引号和双引号的字符序列必须在同一行上
- 而三引号内的字符序列可以分布在多行。
- 请注意,字符串两边的单引号 '' 或双引号 "" 本身只是一种表示方式,并不是字符串的一部分。
a = '我是字符串'
b = "我也是字符串"
c="""我还是字符串
中间可以写任何文字、数字12435436
字符串分布在多行"""(1)字符串的索引
- 字符串也可以被截取(检索)。类似于 C ,字符串的第一个字符索引为 0 。
- Python 没有单独的字符类型 (char) ;一个字符就是一个简单的长度为 1 的字符串。

word = 'Python'
print(word[3]) # h索引也可以是负数,这样的话就会从字符串的右边开始计算:

word = 'Python'
print(word[-2]) # o(2)字符串的切片
索引用于获得单个字符,切片让你获得一个子字符串。
切片语法格式:
sname[start : end : step]
- sname:序列的名称
- start:切片的开始位置,包括该位置(如果不写,默认为0或-1)
- end:切片的截止位置,不包括该位置(如果不写,默认是start的另一端)
- step:切片步长,不写的话默认为1**,** (如果是正数意味着从左取到右,负数意味着从右取到左)
【注意】:选区的区间属于左闭右开型,
即从“start”位开始,到**“end”位的前一位结束(不包含结束位本身)**。
word = 'Python'
print(word[0:2]) # Py
print(word[:2]) # Py
print(word[::2]) # Pto
print(word[2:5:]) # tho
print(word[5:2:-1]) # noh(3)字符串的常用方法
len()计算字符串长度
print(len("人生苦短,我用Python") ) # 13
# 通过len()函数计算字符串的长度时,
# 不区分英文、数字、汉字以及符号,
# 所有字符都按一个字符计算。字符串可以通过加法和乘法进行连接和重复:
print("Python" + "ABCD") # PythonABCD
print("Python" * 3) # PythonPythonPython
print("Python" * 3 + 'ABD'*2) # PythonPythonPythonABDABD除了采用切片的方法,字符串对象提供了其他的字符串查找方法:
# 判断元素是否存在
print('y' in 'Python') # True
print("m" in "python") # Flase
count()计算子串个数:pythona = '我爱北京天安门,天安门上太阳升' a.count("天安门") # 2
find()查找:pythona = "这是一个查找是的函数" print(a.find('是')) # 1 # 注意:find()返回的是索!引!值! # 返回查找到的第一个元素的索引值 (a有两个'是',找到第一个就返回了) print(a.rfind('是')) # 6 # rfind()返回的是最后一次出现的位置 # 注意 rfind()不是从右边查找!!! print(a.find("m")) # -1 #如果对象不在字符串内,则返回-1
index()查找:index() 方法同find() 方法基本一样,也是用于检索字符串类是否包含特定的对象,返回的也是索引值 只不过如果要检索的对象如果不存在于字符串内,不会像find()一样返回-1,而是直接报错
pythonb = "这是一个查找函数" print(b.index('一')) # 2 # print(b.index('我')) # ValueError: substring not found
(4)字符串的合并
连接字符.join(序列)合并序列方法 :pythonprint("--".join("Python")) # P--y--t--h--o--n # 使用字符将后面的序列连接起来 print(" ".join("Python")) # P y t h o n print("--".join("我就是喜欢这么说话你来打我啊!")) # 我--就--是--喜--欢--这--么--说--话--你--来--打--我--啊--! print("*".join('小星星也很可爱哦~')) # 小*星*星*也*很*可*爱*哦*~ # 序列也可以是其他的数据类型(比如:列表) print(" ".join(["just","do","it"])) # just do it
(5)字符串的分割
split()方法:pythons1 = "123哈 254哈 354534哈 4646" # 切割字符串,默认在空白处切分 # 返回值是列表,可以用变量接收 li1 = s1.split() print(li1) # ['123哈', '254哈', '354534哈', '4646'] li2 = s1.split("哈") # 也可以在指定位置切割 print(li2) # ['123', ' 254', ' 354534', ' 4646'] li3 = s1.split("哈",2) # 还可以传入参数去限制分割几次 print(li3) # ['123', ' 254', ' 354534哈 4646'] # 如果想从右边开始分隔(还是加个“r”): # 注意,这个r就是右边开始了,前面的rfind() 是返回最后一个 li4 = s1.rsplit("哈",2) print(li4) # ['123哈 254', ' 354534', ' 4646']
splitlines()方法按照行分隔,返回一个包含各行作为元素的列表。
mystr.splitlines() 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表。 如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
pythona ="我说你是人间的四月天\r笑响点亮了四面风\r\n轻灵在春的光艳中交舞着变\n你是四月早天里的云烟\n黄昏吹着风的软\n星子在无意中闪\n细雨点洒在花前 \n你是一树一树的花开\n是燕在梁间呢喃,——你是爱,是暖\n是希望,你是人间的四月天!" print(a.splitlines()) """ ['我说你是人间的四月天', '笑响点亮了四面风', '轻灵在春的光艳中交舞着变', '你是四月早天里的云烟', '黄昏吹着风的软', '星子在无意中闪', '细雨点洒在花前 ', '你是一树一树的花开', '是燕在梁间呢喃,——你是爱,是暖', '是希望,你是人间的四月天!'] """ # 改参数 keepends b = a.splitlines(True) print(b) """ ['我说你是人间的四月天\r', '笑响点亮了四面风\r\n', '轻灵在春的光艳中交舞着变\n', '你是四月早天里的云烟\n', '黄昏吹着风的软\n', '星子在无意中闪\n', '细雨点洒在花前 \n', '你是一树一树的花开\n', '是燕在梁间呢喃,——你是爱,是暖\n', '是希望,你是人间的四月天!'] """
partition()方法
- 把str以括号中的分隔符为标准,分割成三部分, str前, str 和 str后
pythona = 'abcd哈fgabcd哈123' b = a.partition('哈') print(b) # ('abcd', '哈', 'fgabcd哈123') # 对比 split c = a.split('哈') print(c) # ['abcd', 'fgabcd', '123'] # partition() 保留分割字符 永远为 3 部分 # split() 去除分割字符,按分割字符来划分 # 如果想从右边开始分割(还是加个“r”): d = a.rpartition('哈') print(d) # ('abcd哈fgabcd', '哈', '123')
(6)字符串的替换
replace()方法:
字符串.replace(被替换的字符, 用来替换的字符, 替换次数)pythonprint("人生苦短,我用python".replace("python","java")) # 人生苦短,我用java # 指定替换次数 print("人生苦短,我用python,python,pthon".replace("python","java",1)) # 人生苦短,我用java,python,pthon
(7)去除两端特殊字符
- 删除
str字符串两端的空白字符以及特殊字符- 这里的特殊字符包括制表符
\t、回车符\r、换行符\n
a = " 哈哈 "
print(a.strip()) # 不指定默认去除空白字符
# 哈哈
b = "\t哈哈\r\n"
print(b.strip())
# 哈哈
# 只能去除两端,不能去除中间
c = " \r 哈哈哈%%\t\r哈哈哈\r\n"
print(c.strip())
# 哈哈哈%%\t\r哈哈哈
# 如果指定去除字符左右两边某些字符,在strip()内填入你指定的字符即可。
d = "@@@哈哈¥¥"
print(d.strip("@")) # 哈哈¥¥
print(b.strip("@").strip("¥")) # 哈哈
# 字符串.rstrip()——只去除右边的空格和特殊字符
# 字符串.lstrip()——只去除左边的空格和特殊字符
e = '\n哈哈\t '
print(e.lstrip()) # 哈哈\t
print(e.rstrip()) # \n哈哈(8)字符串的格式化
Python 中有三种格式化操作符,分别是 format 、%s 、 f 。
1. format
此函数可以快速的处理各种字符串,增强了字符串格式化的功能。
基本语法是使用{}和.format()。format函数可以接受不限各参数,位置可以不按照顺序
name = '张三'
age = 18
nickname = '法外狂徒'
# format 用 {} 占位
print('姓名:{},年龄{},外号:{} '.format(name, age, nickname))
# 姓名:张三,年龄18,外号:法外狂徒
print('hello {aa} 你今年已经{bb}岁了'.format(bb = age,aa = name))
# hello 张三 你今年已经18岁了2. f
f'{}'形式,并不是真正的字符串常量,而是一个运算求值表达式,
可以很方便的用于字符串拼接、路径拼接等
name = '张三'
# f 在字符串中嵌入变量
print(f'hello {name} !')
# hello 张三 !3. %s
%被称为格式化操作符,专门用于处理字符串中的格式
- 包含
%的字符串,被称为格式化字符串%和不同的字符连用,不同类型的数据需要使用不同的格式化字符
| 格式化字符 | 含义 |
|---|---|
| %s | 字符串 |
| %d | 有符号十进制整数,%06d 表示输出的整数显示位数,不足的地方使用0补全 |
| %f | 浮点数,%.2f 表示小数点后只显示两位 |
| %% | 输出 % |
| %c | %ASCII字符 |
| %o | %8进制 |
| %x | %16进制 |
| %e | %科学计数法 |
语法格式如下:
pythonprint("格式化字符串 %s" % '变量1') print("格式化字符串" % ('变量1', '变量2', ...))pythonname = '张三' age = 18 nickname = '法外狂徒' name2 = '李四' age2 = 19 nickname2 = '帮凶' # %s 用 %s 占位 print('姓名:%s' % name) # 姓名:张三 # 多个参数 print('%s,%s 哦嗨呦' % (name, name2)) # 张三,李四 哦嗨呦
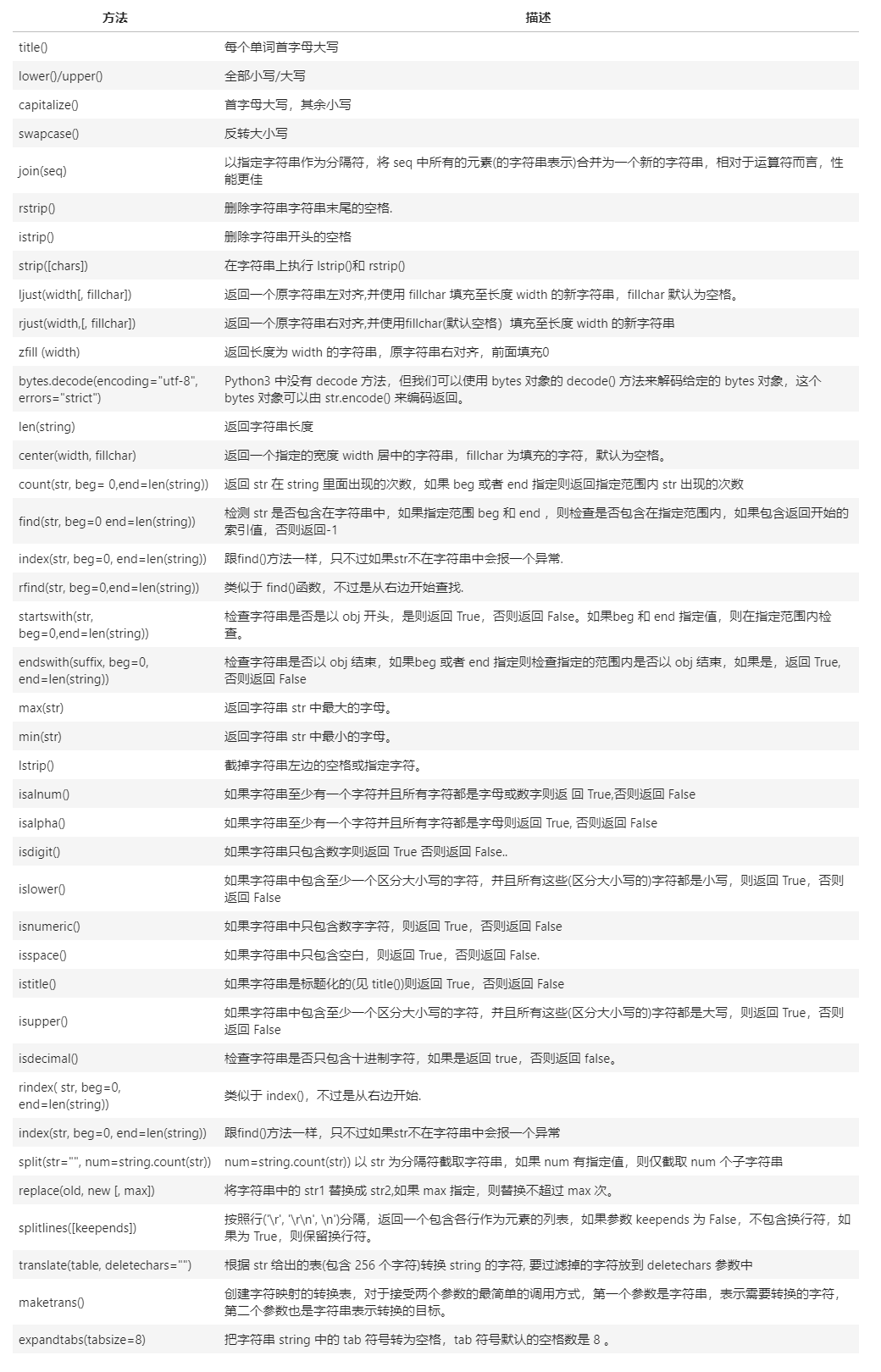
2_4. 字符串方法总览
三、复合数据类型
3_1. 列表 list
Python 的 4 种复合数据类型中最通用的是 list(列表),它可以写作[] (中括号)之间的一列逗号分隔的值。 列表是有序的,并且其中的元素不必是同一类型,且长度没有限制
- 列表和字符串一样,都属于序列。
- 序列的索引、切片、相加、乘法、判断元素存在否、计算长度、最大小值,这些操作列表都支持。
- 当列表元素增加或删除时,列表对象自动进行扩展或收缩内存,保证元素之间没有缝隙(自动内存管理)
li1 = [1, 2,[55,66],'on','go',True,False,None]
print(li1)
# [1, 2, [55, 66], 'on', 'go', True, False, None]
print(type(li1)) # <class 'list'>(1)列表索引与切片
- 列表和字符串一样,是一种可迭代对象.
- 因此列表可以和字符串一样进行索引和切片. 语法方面是一样的.
li1 = [1, 2,[55,66],'on','go',True,False,None]
print(li1[0]) # 1
print(li1[2]) # [55,66]
print(li1[2:4]) # [[55, 66], 'on']
print(li1[-2]) # False❓思考:怎么以切片的形式取出 55 ?
pythonli1 = [1, 2,[55,66],'on','go',True,False,None] print(li1[2][0]) # 55 # 拆解来看 li1[2] 取到了 [55,66] 那对这个再取 [0] 不就是 55
(2)列表元素检索
a = [1,'a', [2, 5]]
print([2,5] in a) # True
# ??思考2是否在列表中?
print(2 in a) # Flase
index()查找 :pythona = ['我','爱','北','京','天','安','门','天','安','门'] print(a.index("门")) # 6 # 可以指定检索的索引范围 print(a.index("门",7,10)) # 9
❗a.find("门") 是错的.... --> 列表不能用find()
count()获得某个元素元素出现次数pythona = ['我','爱','北','京','天','安','门','天','安','门'] print(a.count("门")) # 2
(3)列表元素修改
通过元素的索引位置来修改元素
pythonli1 = [1,2,[33,55],4] li1 = 99 print(li1) # [1, 99, [33, 55], 4]❓ 如何将li1中的55修改成88
python# 还是跟上面一样,链式提取 li1 = [1,2,[33,55],4] li[2][1] = 88 print(li1) # [1, 2, [33, 88], 4]
(4)列表元素添加
append():pythonL = ['Superman','Hulk','Spiderman'] L.append('Leifengxia') #只能添加一个元素 print(L) # ['Superman', 'Hulk', 'Spiderman', 'Leifengxia'] # append() 在列表末尾追加一个元素
expend():pythona = [1,2] b = [3,4] a.append(b) print(a) # [1, 2, [3, 4]] # ----上下对比--------- a = [1,2] b = [3,4] a.extend(b) print(a) # [1, 2, 3, 4] # 可见:如果传一个序列给extend,它会把它先遍历出来再添加
insert():pythonc = [0, 1, 2] c.insert(2, "嘿") print(c) # [0, 1, '嘿', 2] # insert() 第一个参数是指定插入的索引, 第二个参数是插入的值❓ 空列表插入会怎么样
pythond = [] d.insert(100,"hhh") print(d) # ['hhh'] d.insert(100,"aaaaaa") print(d) # ['hhh', 'aaaaaa'] # 超出索引范围会变成追加在末尾
(5)列表元素删除
del:python# 删除某个元素 a = ["a","b","c","d","e"] del a[2] print(a) # ['a', 'b', 'd', 'e'] # 删除某些元素 a = ["a","b","c","d","e"] del a[1:3] print(a) # ['a', 'd', 'e'] # 删除整个列表 del a # print(a) # NameError: name 'a' is not defined. Did you mean: 'id'?
clear():python# 清空列表所有元素 a = ["a","b","c","d","e"] a.clear() print(a) # []
pop():python# 弹出指定位置的元素 a = [11,22,33,43] a.pop() print(a) # [11, 22, 33] # pop() 不指定参数,默认弹出最后一个 a = [11,22,33,43] b = a.pop(1) print(a) # [11, 33, 43] print(b) # 22 # pop()可以指定弹出元素的索引值,且有返回值,可以用变量接收
remove():python# 移除某个指定元素 li1 = ["a","b","c","d","e","c"] li1.remove("c") #移除列表中某个值的第一个匹配项 print(li1) # ['a', 'b', 'd', 'e', 'c']
(6)列表元素排序
sort():pythona = [1, 4, 2, 3] a.sort() # 默认升序 print(a) # [1, 2, 3, 4] a.sort(reverse=True) #降序 print(a) # [4, 3, 2, 1] # sort() 是直接在原列表上排序
sorted():python# 若不想在原列表上修改,可以用sorted() a = [1, 4, 2, 3] b = sorted(a) print(a) # [1, 4, 2, 3] print(b) # [1, 2, 3, 4]
reverse():python# 单纯的逆置 a = [1, 4, 2, 3] a.reverse() print(a) # [3, 2, 4, 1]
reversed():python# 与上面sorted()同理,也有reversed() a = [1, 4, 2, 3] b = reversed(a) print(a) # [1, 4, 2, 3] print(b) # <list_reverseiterator object at 0x000001CFEAFE0220> # 上面b返回的是一个对象,可以用list强转 print(list(b)) # [3, 2, 4, 1]
3_2. 元组 tuple
元组由数个逗号分隔的值组成,与列表非常相似。
元组在输出时总是有括号的,以便于正确表达元组结构,但在输入时可以有或没有括号,不过大多数情况下鼓励使用括号。因为元组是不可变的,所以不能给元组的一个独立的元素赋值(尽管可以通过类似字符串的方式连接和切割来模拟)。但可以创建包含可变对象的元组,例如元组中包含列表。
tup1 = ('physics', 'chemistry', 1997, 2000)
print(tup1) # ('physics', 'chemistry', 1997, 2000)
print(type(tup1)) # <class 'tuple'>
# 可以不带括号,但不鼓励
tup2 = "a", "b", "c", "d"
print(tup2) # ('a', 'b', 'c', 'd')
print(type(tup2)) # <class 'tuple'>当创建空的元组或只包含一个元素的元组时,语法稍稍有些不同。
一对空的括号可以创建空元组,但是一个元素的元组需要加上一个逗号:
tup3 = ()
print(tup3) # ()
print(type(tup3)) # <class 'tuple'>
tup4 = (1,)
print(tup4) # (1,)
print(type(tup4)) # <class 'tuple'>
tup4 = (1)
print(tup4) # 1
print(type(tup4)) # <class 'int'>【注意】由于元组是不可变序列,所以元组中的元素值是不能修改,也不允许删除的,
如果一定要删除元素,可以使用
del语句删除整个元组
3_3. 字典 dict
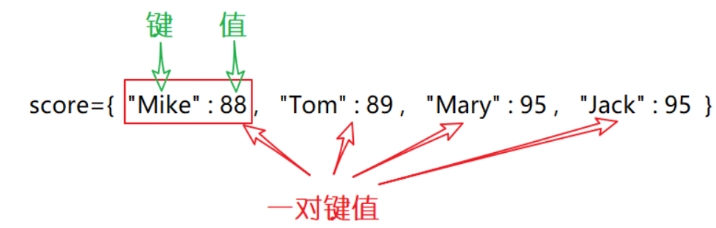
Python内置了字典:dict 的支持,dict 全称 dictionary,在其他语言中也称为 map,
使用键-值(key-value)存储,具有极快的查找速度。
字典由键(key)和对应值(value)成对组成。基本语法如下:
- 每个键与值用冒号隔开(:),每对用逗号,每对用逗号分割,整体放在花括号中({})。
- 键必须独一无二,但值则不必。
- 用 Python 写一个 dict 如下:
pythonscores={"Mike":88,"Tom":89,"Mary":95,"Jack":95} print(scores) # {'Mike': 88, 'Tom': 89, 'Mary': 95, 'Jack': 95} print(type(scores)) # <class 'dict'> scores = dict(Mike=88,Tom=89,Mary=95,Jack=95) print(scores) # {'Mike': 88, 'Tom': 89, 'Mary': 95, 'Jack': 95}
- 【注意】 创建时同一个键不允许出现两次。如果同一个键被赋值两次, 后一个值会被记住,如下所示:
pythonscores={"Mike":88,"Tom":89,"Mary":95,"Mike":95} print(scores) # {'Mike': 95, 'Tom': 89, 'Mary': 95}
- 键必须不可变,所以可以用字符串、数字或元组充当,但不能用列表,如下实例:
pythonscores={("Mike",):88,66:89,"Mary":95,"Mike":95} print(scores) # {('Mike',): 88, 66: 89, 'Mary': 95, 'Mike': 95}
(1)根据键提取值
scores = {"Mike":88,"Tom":89,"Mary":95,"Jack":95}
print(scores["Mike"]) # 88可以通过 in判断key是否存在
pythonscores={"Mike":88,"Tom":89,"Mary":95,"Jack":95} print("lily" in scores) # False
(2)字典赋值或更改
字典名['键名'] = '值名'
- 使用这种方法,如果键名存在,就会修改这个键值名
- 键名不存在的话,就会当作新增加一对键值到字典里面
pythonscores={"Mike":88,"Tom":89,"Mary":95,"Jack":95} scores["Lili"]=66 print(scores) # {'Mike': 88, 'Tom': 89, 'Mary': 95, 'Jack': 95, 'Lili': 66} scores["Tom"]=85 print(scores) # {'Mike': 88, 'Tom': 85, 'Mary': 95, 'Jack': 95, 'Lili': 66}
(3)删除字典元素
| 语句 | 含义 |
|---|---|
| del 字典名['键名'] | 删除指定键值对 |
| 字典名.pop('键名') | 删除键值对 + 弹出值 |
| 字典名.popitem() | 移除并返回字典中的 最后一个插入的键值对 |
| 字典名.clear() | 删除字典内所有元素 和列表对应操作相同 |
| del 字典名 | 删除整个字典 |
del:pythonscores={"Mike":88,"Tom":89,"Mary":95,"Jack":95} del scores['Mike'] print(scores) # {'Tom': 89, 'Mary': 95, 'Jack': 95}
pop():pythonscores={"Mike":88,"Tom":89,"Mary":95,"Jack":95} r = scores.pop('Mike') print(scores) # {'Tom': 89, 'Mary': 95, 'Jack': 95} print(r) # 88 # pop()内必须要传值,因为字典是无序的,即不能通过索引取键值,也不能通过索引删除键值
popitem():pythonscores={"Mike":88,"Tom":89,"Mary":95,"Jack":95} r = scores.popitem() # 弹出最后进来的一对 print(scores) # {"Mike":88,"Tom":89,"Mary":95} print(r) # ('Jack', 95)
(4)字典常用方法
| 方法 | 含义 |
|---|---|
| len(dict) | 计算字典元素个数 |
| dict.keys() | 返回包含该字典键的列表 |
| dict.values() | 返回包含该字典值的列表 |
| dict.items() | 将键值对看成一个元素(作为元组) 并返回装着全部键值对元组的列表 |
scores={"Mike":88,"Tom":89,"Mary":95,"Jack":95}
print(len(scores)) # 4
print(scores.keys()) # dict_keys(['Mike', 'Tom', 'Mary', 'Jack'])
print(scores.values()) # dict_values([88, 89, 95, 95])
print(scores.items())
# dict_items([('Mike', 88), ('Tom', 89), ('Mary', 95), ('Jack', 95)])
# 想要列表的形式就用 list() 强转3_4. 集合 set
集合是一个无序不重复元素的序列。集合中的元素有三个特征:
- 确定性(集合中的元素必须是确定的)
- 互异性(集合中的元素互不相同,如果相同,集合会自动去重)
- 无序性(集合中的元素没有先后之分)
(1)集合的创建
# 用大括号{}创建
s1 = {'a','b','c'}
print(s1) # {'a', 'b', 'c'}
print(type(s1)) # set
# 用set + 字符串创建
s2 = set('abcedf')
print(s2) # {'a', 'b', 'c', 'd', 'e', 'f'}
# 用set+列表/元组创建
print(set(['a','b','c'])) # {'a', 'c', 'b'}
print(set(('a','b','c'))) # {'a', 'c', 'b'}❗ 注意:想要创建空集合,你必须使用 set() 而不是 {} ,后者用于创建空字典
(2) 集合的基本操作
add():python# 可以通过add(key)方法添加元素到set中,但对于已经存在的值不会有效果。 s={1, 2, 3} s.add(4) print(s) # {1, 2, 3, 4} s.add(1) print(s) # {1, 2, 3, 4}
pop():python#删除第一个元素(不能指定弹射某个元素) s={1, 2, 3, 4} r = s.pop() print(r) # 1 print(s) # {2, 3, 4}
remove():pythons={1, 2, 3, 4} s.remove(3) #删除指定元素 print(s) # {1, 2, 4}
clear():pythons={1, 2, 3, 4} s.clear() #清空集合 print(s) # set()
in:python#判断元素是否在集合中 s={1, 2, 3, 4} print(6 in s) # Flase
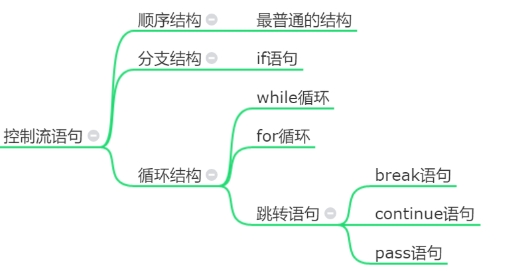
四、控制流语句
在 Python 中,有三种控制流类型:
- 顺序结构
- 分支结构
- 循环结构
复杂的控制流语句都是由这三个基本的控制流组成的。
4_1. 顺序结构
顺序结构是最普通的结构,就是普通的至上而下逐行运行的代码结构。
a = '顺序结构'
print(a) # 顺序结构
b = '自上而下'
print(b) # 自上而下
c = '逐条运行'
print(c) # 逐条运行在顺序结构当中,如果代码在某行出错则后面的代码都不会被执行:
pythona = 111 print(a) # 111 raise NameError # 这里我们故意创建并抛出一个错误 """ --------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-183-84a9659814d5> in <module> 1 a = 111 2 print(a) ----> 3 raise NameError # 这里我们故意创建并抛出一个错误 4 b = 222 # 下面的这两条代码都不会执行 5 print(b) NameError: """ # 下面的这两条代码都不会执行 b = 222 print(b)
4_2. 分支结构
Python 条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。
pythonif <条件判断1>: <执行1> elif <条件判断2>: <执行2> elif <条件判断3>: <执行3> …… else: <执行4>可能会有零到多个 elif 部分,else 是可选的。关键字 "elif" 是 "else if" 的缩写。
if-else结构:pythonage = 17 if age >= 18: print('your age is', age) print('adult') else: print('your age is', age) print('teenager') """ your age is 17 teenager """
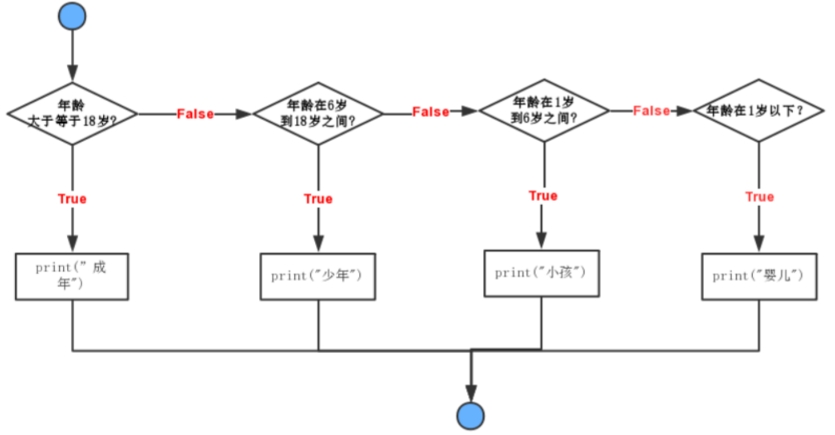
if-elif-else结构:pythonage = 15 if age >= 18: print('成人') elif age >= 6: print('少年') elif age >= 1: print('小孩') else: print('婴儿') # 少年if语句执行有个特点,它是从上往下判断
如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的elif和else
【补充】对于单层的 if-else 语句,可以用
三目运算符简化语法结构:
python# 三目运算符语法 条件为真执行语句体 if 条件 else 条件为假执行语句体python# 普通 if-else 结构 a=10 b=5 if a>b: r="a更大" else: r="b更大" print(r) # a更大python# 三目运算符 # 简化如下: a=10 b=5 print("a更大") if a>b else print("b更大") # a更大
4_3. 循环结构
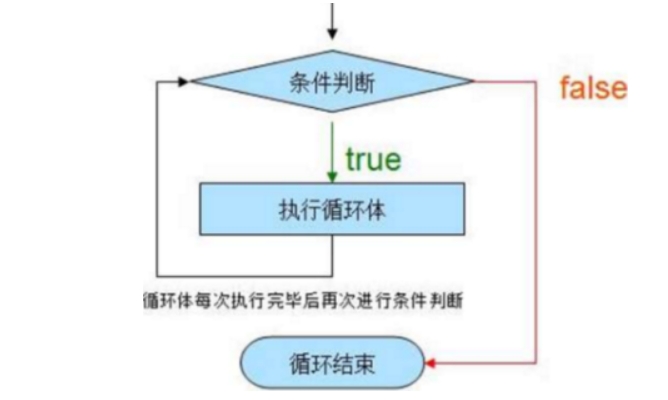
4_3_1. while 循环
只要while后面的条件判断为True,那么就会一直执行循环体内的语句。
pythonwhile 条件: 条件满足时,做的事情1 条件满足时,做的事情2 条件满足时,做的事情3 ...(省略)...
简单
while循环示例:pythoni = 1 while i<=5: print("当前是第 %d 次执行循环" % (i)) #字符串的格式化 print("i = %d " % i) i+=1 # 改变循环变量,否则循环不会终止,相当于 i=i+1 print("循环结束后,这里是循环外,当前的 i 为: " , i)运行结果:
text当前是第 1 次执行循环 i = 1 当前是第 2 次执行循环 i = 2 当前是第 3 次执行循环 i = 3 当前是第 4 次执行循环 i = 4 当前是第 5 次执行循环 i = 5 循环结束后,这里是循环外,当前的 i 为: 6
4_3_2. for循环
像while循环一样,for可以完成循环的功能。
在Python中 for循环可以遍历任何序列的项目,如一个列表或者一个字符串等。
for循环的格式 :
pythonfor 临时变量 in 列表或者字符串等: 循环满足条件时执行的代码
简单
for循环示例 :pythonfor i in range(5): print(i)运行结果:
text0 1 2 3 4【补充】range() 函数是生成一个指定范围内的整数序列,常与 for循环搭配使用
语法 :
range(start,stop[,step])注意:range也是左闭右开的,即不包含 stop
示例:
pythonprint(range(1,5)) # range(1, 5) print(list(range(1,5))) # [1, 2, 3, 4] print(list(range(5))) # [0, 1, 2, 3, 4] print(list(range(1,10,2))) # [1, 3, 5, 7, 9]【剧透】for 循环生成序列可以写成列表推导式
pythonprint([i for i in range(5)]) # [0, 1, 2, 3, 4]
4_3_3. 跳转语句:break&continue&pass
4_3_3_1. break语句
break语句可以终止当前的循环,包括while和for在内的所有控制语句。
这就好比你绕圈跑步,一开始打算跑5圈。
跑了2圈半,突然朋友喊你,你就停下来,不跑了,找朋友去了。
——结束当前循环
此时,算作你跑了2圈。
for循环示例:python# 在for循环中 name = '世界杯在召唤我' for x in name: print('----') if x == '在': break # 当遍历到 '在' 时退出循环 print(x) print("这句话在for循环后,但是和for循环无关") #脱离该循环后程序从循环后代码继续执行运行结果:
text---- 世 ---- 界 ---- 杯 ---- 这句话在for循环后,但是和for循环无关
break语句跳出了最内层循环,但仍然继续执行外层循环。
每个break语句只有能力跳出当前层次循环
示例:
pythonname = '世界杯在召唤我' for i in range(3): for x in name: print('----') if x == '在': break #跳出了最内层循环,但仍然继续执行外层循环 print(x) print(f"\n——————我是{i+1}次大循环结束之后的优美的分割线——————\n") print("\n这句话在for循环后,for循环无关\n")运行结果:
text---- 世 ---- 界 ---- 杯 ---- ——————我是1次大循环结束之后的优美的分割线—————— ---- 世 ---- 界 ---- 杯 ---- ——————我是2次大循环结束之后的优美的分割线—————— ---- 世 ---- 界 ---- 杯 ---- ——————我是3次大循环结束之后的优美的分割线—————— 这句话在for循环后,for循环无关
while循环示例:python# 在while循环中 i = 0 while i<10: i+=1 print('----') if i==5: break print(i)运行结果:
text---- 1 ---- 2 ---- 3 ---- 4 ----
4_3_3_2. continue语句
- continue的作用:用来结束本次循环,紧接着执行下一次的循环。
- 这就好比你绕圈跑步,一开始打算跑5圈。
- 跑了2圈半,发现好像落下钱包在起跑点了,终止跑第二圈。
- 然后你回到起跑点找钱包,找到钱包,然后继续重新跑,算作从第3圈开始跑。
- 这里你要注意的是:
- break用来结束当前代码块的最内层循环。
- continue用来结束当前代码块的本次循环。
for循环示例:python# 在for循环中 name = '世界杯在召唤我' for x in name: print('----') if x == '在': # 当遇到 '在' 跳过本次循环,继续下一次 continue print(x)运行结果:
text---- 世 ---- 界 ---- 杯 ---- ---- 召 ---- 唤 ---- 我
while循环示例:python# 在while循环中 i = 0 while i<10: i = i+1 print('----') if i==5: continue print(i)运行结果:
text---- 1 ---- 2 ---- 3 ---- 4 ---- ---- 6 ---- 7 ---- 8 ---- 9 ---- 10
4_3_3_3. pass语句
pass是空语句,是为了保持程序结构的完整性。 pass 不做任何事情,一般用做占位语句。
pythonfor letter in 'Python': if letter == 'h': pass else: print("当前字母 :",letter)运行结果:
text当前字母 : P 当前字母 : y 当前字母 : t 当前字母 : o 当前字母 : n
五、函数
函数实际上是:
- 代码的一种组织形式
- 一个函数一般完成一项特定的任务
- 函数使用
- 函数需要先定义
- 使用函数,称之为调用
- 函数是组织好的,可以重复使用的,用来实现单一或者相关联功能的代码段。
- 函数能提高应用的模块性和代码的重复利用率。
- python有很多的内置函数,比如print(),type()等等。
- 但自己创建函数也是熟练使用python必备的技能之一。这种自建函数也称作自定义函数。
5_1. 函数的定义及调用
- 我们可以自己定义一个函数,但是需要遵循以下的规则:
- 函数的代码块以def关键字开头,后接函数标识符名称和圆括号()。
- 圆括号用来存储要传入的参数和变量,这个参数可以是默认的也可以是自定义的。
- 函数内容以冒号起始,并且有强制缩进。
- return[表达式]结束函数。选择性地返回一个值给对方调用。不带表达式的return相当于返回None。
def 函数名(<参数>):
……
return [表达式]简单示例:
pythondef hehe(): print("我是一个函数") #调用上面定义的函数 #直接函数名后面跟括号就可以实现: hehe() hehe() hehe()运行结果:
text我是一个函数 我是一个函数 我是一个函数
5_2. 函数的参数
现在,我们可以去看看括号里面的东西了!
括号里面其实是函数的参数,不含参数的函数就像一个对同样代码的打包程序,
这跟使用循环语句没什么区别。
参数可以使每次调用的函数有不同的实现,加入参数的概念,使函数的功能越发的强大,
将其与循环语句从本质上区别开来。
大大简化了重复编写类似程序的负担。
形参和实参 :
参数从调用的角度来看,分为形式参数(parameter) 和 实际参数(argument)
跟绝大多数语言类似,形参是指函数创建和定义过程中的参数,
而实参则是指函数在调用过程中实际传递的参数。
定义时小括号中的参数,用来接收参数用的,称为 “形参”
调用时小括号中的参数,用来传递给函数用的,称为 “实参”
pythondef truth(name): print(name + "怎么这么帅!") truth("irai")运行结果:
textirai怎么这么帅!

位置参数:须以正确的顺序位置传入函数,调用时的数量和位置必须和声明时的一样。python# 函数定义 def divi(x, y): return x / y # 函数调用 divi(2,3)text0.6666666666666666
关键字参数:通常在调用一个函数的时候,如果一个函数中的参数不止一个,
那么记得每一个参数的位置是一个很困难,并且很容易出错的问题。
pythondef suggest(language,word): print(language + " --> " + word) suggest("java","狗都不学") suggest("狗都不学","java")运行结果:
textjava --> 狗都不学 狗都不学 --> java此时,使用关键字参数则可以简单的解决潜在的问题,我们可以通过以下的例子进行体会:
pythondef suggest(language,word): print(language + " --> " + word) suggest(word="狗都不学",language="java")运行结果:
textjava --> 狗都不学这样,我们传实际参数就不会被位置影响~
注意!关键参数是在调用函数的时候使用,而不是在定义函数的时候使用
默认参数:我们学习了关键词参数之后,还需要去理解默认参数。因为初学者很容易将二者搞混。
默认参数实际上是在定义函数的时候赋予了默认值的参数。
一个函数参数的默认值,仅仅在该函数定义的时候,被赋值一次。
如此,只有当函数第一次被定义的时候,才讲参数的默认值初始化到它的默认值(如一个空的列表)。
使用默认参数时一定是指向不可变对象,这里主要为防止反复调用过程中出现问题。
pythondef truth(name,word="怎么这么帅"): print(name,word) truth("irai")运行结果:
textirai 怎么这么帅
- 形参word被定义了默认值"怎么这么帅"。
- 在调用函数的时候,当word没有传递任何实参时,就会使用默认值
调用函数的时候,即使所有形参都不使用,直接写实参,
都可以按照既定的位置将实参传输到对应的位置,如下:
pythondef truth(name,word="怎么这么帅"): print(name,word) truth("他","是真的帅")运行结果 :
text他 是真的帅
关键字参数和默认参数的区别:
关键词参数
在函数调用的时候必须要带参数调用,通过参数名指定要赋值的参数,
这样做就不怕因为不清楚参数的顺序而导致函数调用出错。
——————————————————————————————————————
默认参数
是在参数定义的过程中,为形参赋初值,当函数调用的时候不传递实参时,
则默认使用形参的初始值代替。
5_3. return语句
return[表达式]语句用于退出函数,选择性地向调用方法返回一个表达式。不带参数值的return语句返回None。之前的例子没有示范返回值,下面我们来演示一下return语句的用法:
pythondef sums(arg1 , arg2): print("这句话在return语句之前,执行本函数会输出") cc=arg1 + arg2 return cc print("这句话在return语句之后,执行本函数不会输出") r = sums(10,55) print(r)运行结果:
text这句话在return语句之前,执行本函数会输出 65
例子:定义一个计算面积的函数
pythondef area(width, height): area = width * height return area result1 = area(4,5) print(result1) # 20 result2 = area(height=6,width=5) print(result2) # 30
5_4. 匿名函数:lambda表达式
python 允许使用
lambda创建匿名函数。这个匿名函数我们通过字面意思可能不太好理解,
但是通过下面的两个例子,相信大家很快就能理解:
1)一个参数的例子:
python# 正常函数 def someFunc(x): return 2*x+1 print(someFunc(3)) # 7 # lambda aa = lambda x: 2*x+1 print(aa(4)) # 92)两个参数的例子:
python# 正常函数 def someFunc_1(x,y): return x + y print(someFunc_1(5,6)) # 11 # lambda gg = lambda x,y : x + y print(gg(5,6)) # 11小结:
- lambda 函数的应用场景:
- python 编写一些程序的脚本时,使用 lambda 就可以省下来定义函数的过程。比如写一个简单的脚本管理服务器,就没有必要定义函数,再去调用它。直接使用 lambda 函数,可以使程序更加简明。
- 一些只需要调用一两次的函数,就 没有必要为了想个合适的函数名字而费精力 了,直接使用 lambda 函数就可以省去取名的过程。
- 阅读普通函数,通常需要跳到开头 def 定义的位置,使用 lambda 函数可以省去这样的步骤。
5_5. range函数
range是一个惰性函数,它能够生成一段左闭右开的整数范围。 语法:
range(start, stop [,step])
- start 指的是计数起始值,默认是 0;
- stop 指的是计数结束值,但不包括 stop ;
- step 是步长,默认为 1,不可以为 0 。-1 就是从最后一个逆序。
(了解) 惰性函数(Lazy Function)是指在计算机编程中,一个函数或方法在被调用时不会立即执行其操作,而是在需要结果时才进行计算。这种设计模式通常用于优化性能,特别是在处理可能不会用到的结果或者需要大量计算资源的情况下。
惰性函数的特点包括:
- 延迟计算(Lazy Evaluation):函数的执行被推迟到其结果被实际需要的时候。
- 按需计算:只有在函数的结果被请求时,函数才会执行。
- 节省资源:如果函数的结果最终没有被使用,那么可以节省计算资源。
- 提高效率:对于复杂的计算,可以提高程序的效率,因为避免了不必要的计算。
pythonprint(range(10)) # range(0, 10) # 上一条语句就是 “惰性” 所在 , 不需要时不会解开 print(list(range(10))) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print([*range(10)]) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # “解开range” 可以用list()强转, 也可以用 * 解开, 外面放中括号 # 指定步长 print(list(range(2,8,2))) # [2, 4, 6] # 逆序 print(list(range(1,5,-1))) # [5, 4, 3, 2]
5_6. zip函数
语法:
zip(*iterables, strict=False)参数
iterable为可迭代的对象,并且可以有多个参数。参数
strict默认为 False,如果 strict 为 True,并且其中一个参数在其他参数之前用尽,则引发 ValueError。
该函数返回一个以元组为元素的列表,其中第 i 个元组包含每个参数序列的第 i 个元素。
返回的列表长度被截断为最短的参数序列的长度。(strict为False不会报错)
只有一个序列参数时,它返回一个 1元组的列表。
没有参数时,它返回一个空的列表。
示例:
pythona = [1,2,3,4,5] b = "python123" print(len(a)) # 5 print(len(b)) # 9 print(zip(a,b)) # <zip object at 0x000001DB7D1876C0> print(list(zip(a,b))) # [(1, 'p'), (2, 'y'), (3, 't'), (4, 'h'), (5, 'o')] print([*zip(a,b)]) # # [(1, 'p'), (2, 'y'), (3, 't'), (4, 'h'), (5, 'o')]配合
for循环巧用:pythonrank = ["第一","第二","第三"] name = ["张三","李四","王五"] for r,n in zip(rank,name): print(r+ " --> " + n)运行结果:
text第一 --> 张三 第二 --> 李四 第三 --> 王五
5_7. filter函数
filter函数就是一个过滤器。我们每天都会接触到大量的数据,过滤器的作用就显得格外重要,通过过滤器,就可以保留我们关注的信息,把其他不感兴趣的东西直接丢掉。
filter()有两个参数。第一个参数可以是一个函数,也可以是一个None。
如果是第一个参数是函数的话,则将第二个迭代数据里的每一个元素作为函数的参数进行计算,
把返回True的值筛选出来, 然后返回;
如果第一个参数为None,则直接将第二个参数中为True的值筛选出来。下面举个例子:
pythonprint(filter(None,[1,2,0,False,True])) # <filter object at 0x0000019214B97070> temp = filter(None,[1,2,0,False,True]) print(list(temp)) # [1, 2, True]例子:利用filter(),尝试写一个筛选奇数的过滤器:
pythondef is_odd(n): return n % 2 # 如果n是偶数,n%2返回0,则返回假,会在下面filter()函数被过滤掉 print(filter(is_odd,range(10))) print(list(filter(is_odd,range(10))))运行结果:
text<filter object at 0x000001AA55147010> [1, 3, 5, 7, 9]
5_8. map函数
map 在这里不是地图的意思,在编程领域,map一般做 “映射” 来解释。
map() 也有两个参数,一个是函数,一个是可迭代序列,
将序列的每一个个元素作为函数的参数进行运算加工,
直到可迭代序列每个元素加工完毕,返回所有加工后的元素构成的新序列。
- 灵感:可以看成我们学数学时的
f()
- 数学 :
x --> f()--> y- map :
第二个参数遍历出来的元素 --> 第一个参数 --> 返回值有了刚才filter() 的经验,在这里举个map() 函数的例子:
pythondef is_odd(n): return n % 2 # filter print(list(filter(is_odd,range(10)))) # [1, 3, 5, 7, 9] # map print(list(map(is_odd,range(10)))) # [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] # filter()过滤后,返回的是结果为真(即不等于0)的对象 # 而map()遍历,返回的是计算结果❓思考:一次输入,包含三个数字,用空格分隔,输出三个数字的和 (一条语句完成!)
pythonprint(sum(map(int,input().split())))运行:
python3 4 5 12体验
匿名函数lambda的妙用 :pythonprint(list(map(lambda x:x*2,range(5))))运行结果:
text[0, 2, 4, 6, 8]
5_9. enumerate 函数
enumerate 中文意思 : vt. 列举;枚举;计算
枚举可迭代序列的元素值及其索引,并将元素值及其索引以元组的方式返回。
需要注意的是enumerate函数也是一个惰性函数。
示例:
pythons = "python" print(enumerate(s)) print(list(enumerate(s))) print([*enumerate(s)])运行结果:
text<enumerate object at 0x00000194264C2940> [(0, 'p'), (1, 'y'), (2, 't'), (3, 'h'), (4, 'o'), (5, 'n')] [(0, 'p'), (1, 'y'), (2, 't'), (3, 'h'), (4, 'o'), (5, 'n')]
六、异常与错误
在编写代码的过程中,不可避免的总会出现各种各样的错误。
但是,出现报错并不可怕,只要知道是什么样的错误类型,
你就可以采取相应的措施进行debug。下面我们先来认识一下各种错误类型。
6_1. 语法错误(Syntax Errors)
语法错误, 也就是解析时错误。
当我们写出不符合python语法代码时, 在解析时会报SytaxError, 并且会显示出错的哪一行,
并且用小箭头指明最早探测到错误的位置。
程序运行之前就会预先检查语法错误, 因此报出语法错误的时候程序实际上还没有运行.
比如 elif 后面本该跟条件的,没写就会如下:
pythona=2 b=1 if a>b: print("a更大") elif: print("b更大") """ File "<ipython-input-76-c6fe83290c48>", line 5 elif: ^ SyntaxError: invalid syntax """
6_2. 异常(Exception)
即使语句或表达式在语法上是正确的, 但在尝试运行时也可能发生错误,
运行时错误就叫做异常(Exception).
异常并不是致命问题, 因为我们可以在程序运行中对异常进行处理.
1. 除零错误ZeroDivisionError
print(10/0)
"""
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[1], line 1
----> 1 print(10 / 0)
ZeroDivisionError: division by zero
"""2. 命名错误NameError
print(ok)
"""
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[2], line 1
----> 1 print(ok)
NameError: name 'ok' is not defined
"""3. 类型错误TypeError
print(2 + '2')
"""
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[3], line 1
----> 1 print(2 + '2')
TypeError: unsupported operand type(s) for +: 'int' and 'str'
"""6_3. python标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 好像是读取异常 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
6_4. 异常处理语句:try...except语句
当你知道你的代码可能会产生某种异常, 但是你却不希望, 当这种异常出现的时候导致程序终止,
你想要让程序即使出现了异常也能跳过去继续向下运行,
这时候你就需要添加try/except 或try/finally语句来处理它。
pythontry: 代码块1(可能会出错的代码块放这里) except: 代码块2(如果代码块1出错了,运行代码块2) else: 代码块3(如果代码块1没出错了,运行代码块3) finally: 代码块4(不论代码块1是否正确,都运行代码块4)
示例:
pythontry: a=int(input("请输入行驶公里数(km):")) b=int(input("请输入行驶时间(h):")) c=int(a/b) except : #捕捉所有异常 print("代码有错")运行:
text请输入行驶公里数(km): 100 请输入行驶时间(h): sdhglang 代码有错如果我们预先知道代码可能会有哪些错误,可以提前防止好 “捕捉器”:
pythontry: a=int(input("请输入行驶公里数(km):")) b=int(input("请输入行驶时间(h):")) c=int(a/b) except ZeroDivisionError : #只捕捉除数为0的异常 print("零除错误")运行:
text请输入行驶公里数(km): 100 请输入行驶时间(h): 0 零除错误捕捉异常并打印原因 :
pythontry: 1/0 except ZeroDivisionError as e: #只捕捉除数为0的异常,并记录异常原因在e print("零除错误:",e) #打印异常原因运行:
text零除错误: division by zero
try...except...else语句
上面我们用 try...except 语句来捕捉代码块的异常,但是如果代码块没有异常呢?
如果没有代码异常我们想继续运行代码,那么后续的代码我们可以写在else子句中。
pythontry: a=input("请输入行驶公里数(km):") b=input("请输入行驶时间(h)") c=int(a)/int(b) except (ValueError,ZeroDivisionError) as e_01: # 和int(b)不能为0相比,a和b不能为非数字型字符串更早进入try子句, # 因此要把最早可能出现的错误记为"错误原因1" print("出现两大错误之一,错误原因是:",e_01) # Exception 可以捕抓所有错误类型 except Exception as e_02: print("出现两大错误以外的错误:",e_02) else: print("\n""代码运行没错") print("行驶速度为 %s km/h"%c)运行 1:
text请输入行驶公里数(km): 123 请输入行驶时间(h) 0 出现两大错误之一,错误原因是: division by zero运行 2 :
text请输入行驶公里数(km): 123 请输入行驶时间(h) 2 代码运行没错 行驶速度为 61.5 km/h
try...except...else...finally语句
有些语句,无论是否有异常,都需要运行的,我们可以放在finally子句中。
pythontry: a=input("请输入行驶公里数(km):") b=input("请输入行驶时间(h)") c=int(a)/int(b) except (ValueError,ZeroDivisionError) as e_01: # 和int(b)不能为0相比,a和b不能为非数字型字符串更早进入try子句, # 因此要把最早可能出现的错误记为"错误原因1" print("出现两大错误之一,错误原因是:",e_01) except Exception as e_02: print("出现两大错误以外的错误:",e_02) else: print("\n""代码运行没错") print("行驶速度为 %s km/h"%c) finally: print("\n""全部代码运行完毕") print("无论代码有没有错,都会打印上面这句话")运行:
text请输入行驶公里数(km): 123 请输入行驶时间(h) 1 代码运行没错 行驶速度为 123.0 km/h 全部代码运行完毕 无论代码有没有错,都会打印上面这句话
6_5. 手动引发错误
异常可以用raise语句手动引发,比如:
pythona = 123 b = 0 if b == 0: raise ZeroDivisionError("b不能为0")运行:
textTraceback (most recent call last): File "E:\iraionly\docs\Python\py_note\code\demo.py", line 156, in <module> raise ZeroDivisionError("b不能为0") ZeroDivisionError: b不能为0为什么要引发异常呢?皮一下就开心了吗?又有什么用呢?
其实,有时候我们确实需要把异常引发。
比如我们用python模拟抛色子的时候,如果色子点数大于7或者小于1就不对了,
这时我们可以设置让它报错:
pythonimport random num = random.randint(-10, 10) print(num) if not 1<=num<=6: raise ValueError('随机生成的骰子不合常理') else: print('您摇出的骰子是', num)运行 1 :
text5 您摇出的骰子是 5运行 2 :
text--------------------------------------------------------------------------- ValueError Traceback (most recent call last) Cell In[8], line 7 4 print(num) 6 if not 1<=num<=6: ----> 7 raise ValueError('随机生成的骰子不合常理') 8 else: 9 print('您摇出的骰子是', num) ValueError: 随机生成的骰子不合常理